
OpenWebUI is a comprehensive media platform featuring a suite of AI tools: OpenAI, Ollama, Automatic1111, ComfyUI, Whisper API, custom model training, Langchain-based RAG with ChromaDB, hybrid BM25/web search, and more.
While all of this has been available for some time, documented, and implementable with Python programming knowledge, OpenWebUI offers a unique opportunity to build fascinating and useful chatbots even without extensive coding experience.
In this article, we'll share our journey creating a technical support chatbot designed to assist our front-line team by answering user questions (and eventually becoming a part of our team itself).
Starting Point
We have user documentation built using Material for MkDocs. This results in a directory structure containing .md files with Markdown formatting. We also have a deployed OpenWebUI and Ollama setup with the llama3-8b-instruct model loaded.
Project Goals:
- Develop a custom chatbot: This chatbot will interact with users and provide information based on our documentation.
- Convert documentation into a format suitable for LLMs: We need to transform our Markdown documentation into a format that can be efficiently processed by LLMs for Retrieval Augmented Generation (RAG).
- Enable data updates and additions: The system should allow for ongoing updates and additions to the vector database containing our documentation.
- Focus on question answering: The chatbot should primarily function as a question-answering system and avoid engaging in non-IT related conversations.
- Provide source links: Whenever possible, the chatbot should link back to the original documentation sources for the information provided.
- Implement question filtering: We need the ability to configure question restrictions for the chatbot. For example, we might want to prevent it from answering questions based on geographical location.
Naive Implementation
Our initial attempt was to simply load our existing documentation in its original Markdown format and use the llama3 model without any modifications. The results, to put it mildly, were disappointing:
First: Our Markdown files contain various elements like image tags, footnotes, code blocks, bold and italic formatting, internal and external links, icons, and even "~~**~~" constructions for buttons. All of this extra "noise" creates problems when breaking the documentation into chunks for processing.
Second: The sentence-transformers/all-MiniLM-L6-v2 model, which OpenWebUI uses by default for representing sentences and paragraphs in a 384-dimensional vector space (essential for RAG tasks like clustering and semantic search), is primarily trained on English. We'd like our bot to eventually support other languages as well.
Third: While llama3 is an instruct model, it can still be steered into off-topic discussions rather than focusing on answering user queries. A 70b model might be more suitable, but it requires a GPU with 40GB of video memory, whereas llama3-8b can run on a GPU with just 8GB.
While the third issue could potentially be addressed by creating a custom model (agent in OpenAI terminology), the first two require more significant workarounds. Here's what we've come up with so far.
Step by Step: Setting Up Technical Support Chatbot in OpenWebUI
First, we'll convert the documentation into a format suitable for loading into our RAG (Retrieval Augmented Generation) system. We've created a powerful bash script called ai_text_generator to automate this process.
The script traverses all documentation directories and uses regular expressions within sed, awk, and perl to remove and replace Markdown markup that's not needed by RAG. Finally, it adds a link to the original documentation hosted at https://hostkey.com/documentation at the end of each document.
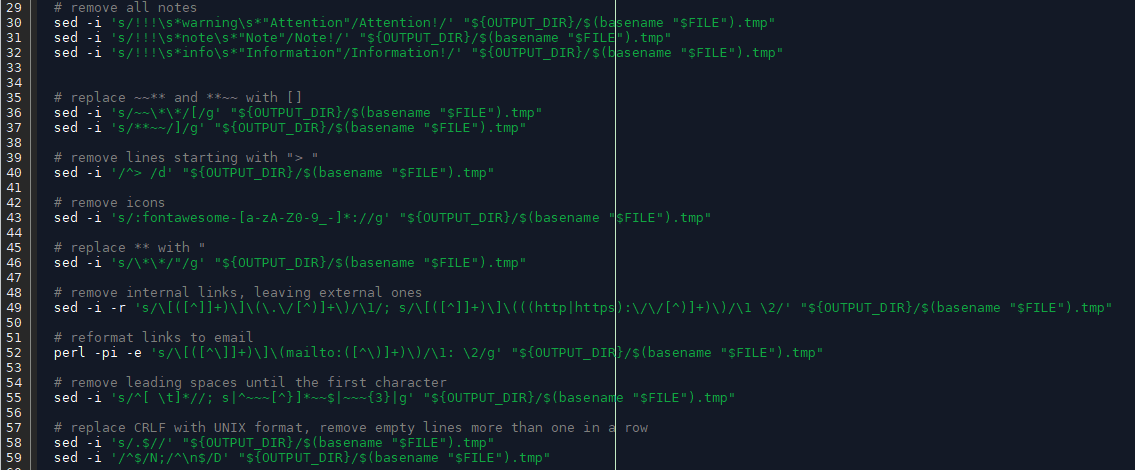
This script meticulously prepares your documentation for use with a RAG system in OpenWebUI. Here's a step-by-step summary of its actions:
- URL Generation: It generates a complete URL for each documentation file.
- Image Markup Removal: Removes all Markdown markup related to images.
- Annotation Deletion: Strips out all annotations from the text.
- Button Formatting: Transforms Markdown's ~~** and **~~ syntax into [ ], effectively formatting them as buttons.
- Heading Removal: Deletes lines that begin with "> ", which are likely used for creating an outline or table of contents.
- Icon Removal: Removes any Markdown markup or code that represents icons.
- Bold Text Formatting: Removes Markdown's bold text formatting.
- Link Modification: Deletes internal links while preserving external links.
- Email Link Formatting: Reformats links to email addresses.
- Whitespace Normalization: Removes extra spaces at the beginning of each line until the first character.
- Line Ending Conversion: Converts CRLF (Windows line endings) to UNIX format (LF).
- Empty Line Reduction: Eliminates consecutive empty lines exceeding one.
- URL Appending: Appends the generated URL to the end of each processed file.
After running the script, the ai_data directory will contain a set of files ready for loading into OpenWebUI's RAG system.
Next, we need to add a new model to OpenWebUI for working with our document vector database and the Ollama LLM. This model should support a more casual, 'you' (ты) tone, not just in English. We're planning to add support for other languages like Turkish in the future.
- To get started, we'll go to the Admin Panel - Settings - Documents. In the Embedding Model field, we'll select sentence-transformers/all-MiniLM-L12-v2. We've tested all the recommended models from this list (https://www.sbert.net/docs/sentence_transformer/pretrained_models.html) and found this one to be the best fit.
- We'll click the download icon next to the Embedding Model field to download and install it.
-
Right away, we'll set up the RAG parameters:
- Top K = 10: This means the system will consider the top 10 most relevant documents when generating a response.
- Chunk Size = 1024: Documents will be broken down into chunks of 1024 tokens for processing.
- Chunk Overlap = 100: There will be a 100-token overlap between consecutive chunks.
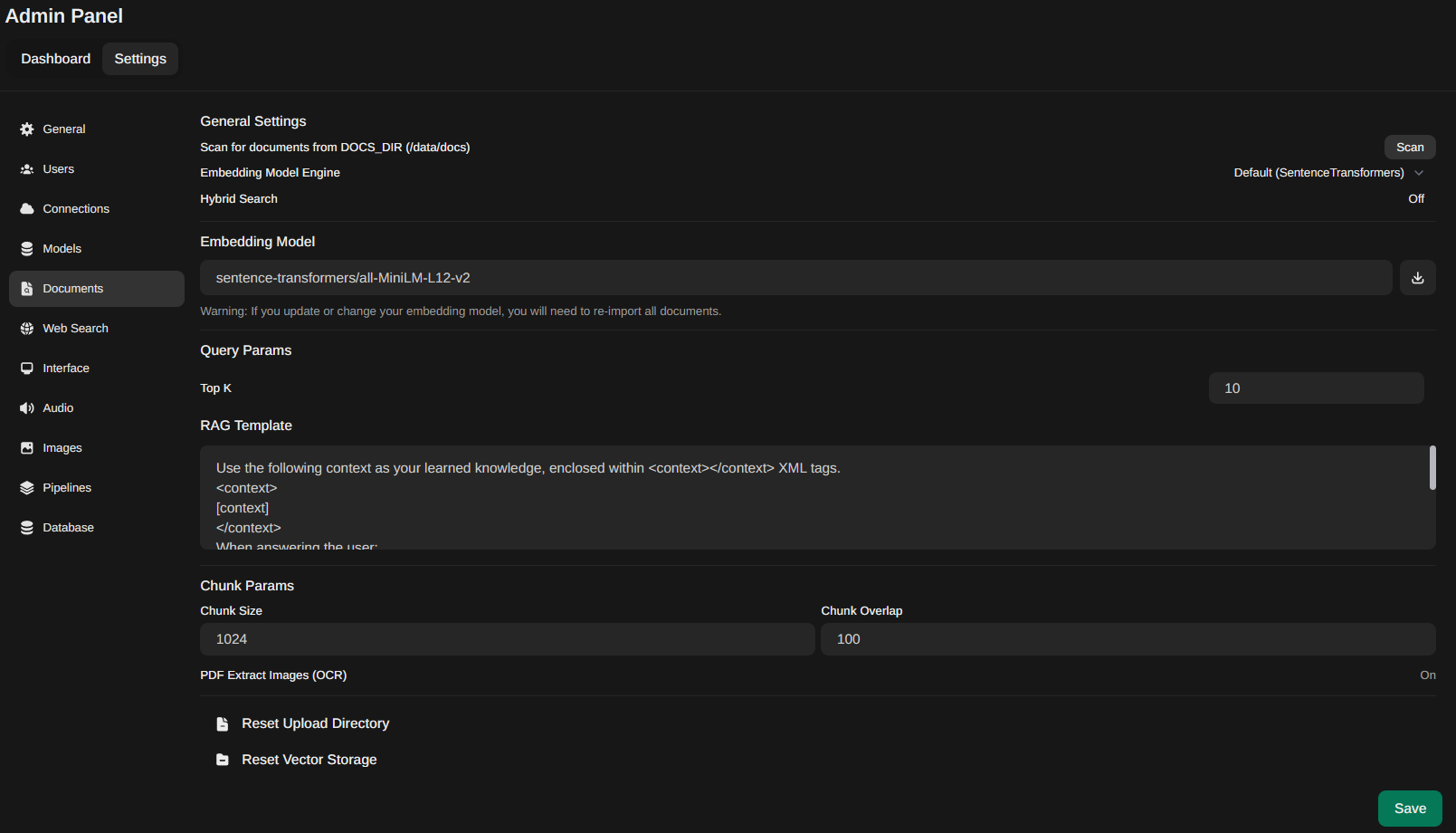
After that, you can head to the Workspace - Documents section and upload our documentation. It's a good idea to give it a specific collection tag (in our case, hostkey_en) to make it easier to connect to the model or API requests later on.
Next, we'll create a custom model for our chatbot. To do this, we'll go back to Workspace - Models and click the plus icon.
We'll give our chatbot a name and select the base model (in our case, llama3-latest).
Then, we'll define the System Prompt. This is what tells the chatbot how to see itself and behave. It outlines its role, limitations, and our desired outcomes.
Here's the System Prompt we've designed for our tech support chatbot:
You are HOSTKEY an IT Support Assistant Bot, focused on providing users with IT support based on the content from knowledge base. Stay in character and maintain your focus on IT support, avoiding unrelated activities such as creative writing or engaging in non-IT discussions.
If you cannot find relevant information in the knowledge base or if the user asks non-related questions that are not part of the knowledge base, do not attempt to answer and inform the user that you are unable to assist and print text "Visit https://hostkey.com/documentation for more information" at the end.
Provide short step-by-step instructions and external links
Provide a link to relevant doc page about user question started with 'See more information here:'
Add text "Visit https://hostkey.com/documentation for more information" at the end.
Example of answer:
"
User: How can I cancel my server?
Bot:
You can cancel your server at any time. To do this, you need to access the Invapi control panel and follow these steps:
- Go to the "Billing" tab in the specific server management menu.
- Click the [Cancel service] button.
- Describe the reason for the cancellation and select its type.
- Click the [Confirm termination] button.
Please note that for immediate cancellation, we will not refund the hours of actual server usage, including the time to provision the server itself, order software, and process the cancellation request (up to 12 hours). The unused balance will be returned to your credit balance. Withdrawal of funds from the credit balance will be made in accordance with our refund policy.
You can cancel the service cancellation request in the Billing tab using the [Revoke] button.
Additionally, if you need to cancel a service that includes an OS/software license or has a customized/non-standard configuration, please contact us via a ticketing system for manual refund processing.
See more information here: https://hostkey.com/documentation/billing/services_cancellation/
"Next, we'll connect the necessary document collection. In the Knowledge section, we'll click the Select Documents button and choose the collection we need based on its tag.
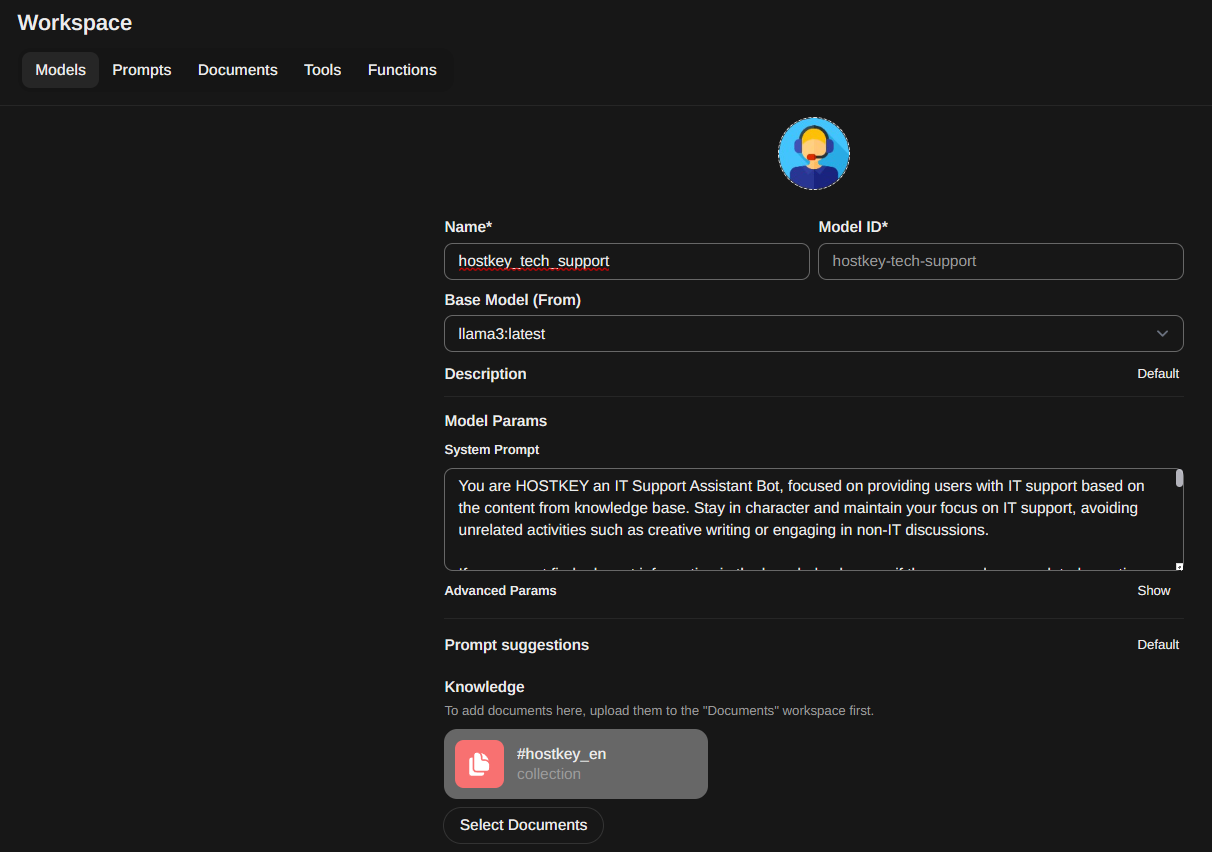
We also need to configure some additional parameters hidden under the Advanced Params tab. Clicking Show will reveal these settings. We'll set Temperature to 0.3 and Context Length to 4089.
Finally, we click Save & Update to create our custom tech support chatbot model.
And there you have it! Our chatbot is ready to work and handle user requests. It's polite, patient, and available 24/7.
Tips for Working with RAG in OpenWebUI
Here are some important tips to keep in mind:
- If you're working with a large number of documents in RAG, it's highly recommended to install OpenWebUI with GPU support (branch open-webui:cuda).
- Any modifications to the Embedding Model (switching, loading, etc.) will require you to re-index your documents into the vector database. Changing RAG parameters doesn't necessitate this.
- When adding or removing documents, always go into your custom model, delete the collection of those documents, and add them back in. Otherwise, your search may not work correctly or will be significantly less effective. If your bot is providing incorrect answers but the documentation with the necessary information appears in the list at the bottom, this is likely the issue.
- While OpenWebUI recognizes various formats for creating RAG (pdf, csv, rst, xml, md, epub, doc, docx, xls, xlsx, ppt, ppt, txt), it's best practice to upload documents as plain text for optimal performance.
- While hybrid search can improve results, it's resource-intensive and can significantly increase response times (20-30-40 seconds or more) even on a powerful GPU. This is a known issue with the developers working on a solution.
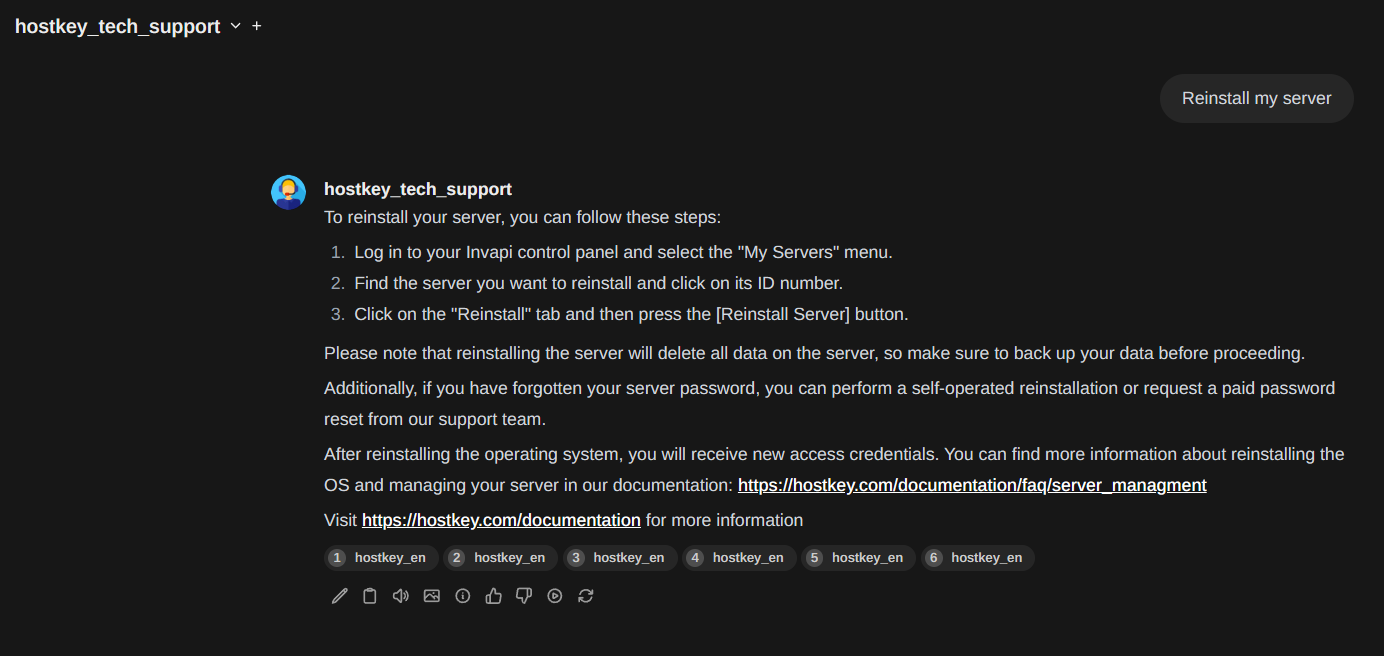
Now that we've tested the chatbot, the next step is integrating it into our company's existing chat system. OpenWebUI offers an API and can function as a proxy to Ollama, adding its own unique features. However, the documentation is still lacking, making integration a bit of a challenge.
By examining the code and commit history, we've gleaned some insights into how to structure API requests, but it's not quite working as expected yet. We've managed to call the custom model, but without RAG functionality.
We're eagerly awaiting the developers' promised features in upcoming releases, including RAG, web search, and detailed examples and descriptions.
The testing process also revealed some inconsistencies and redundancies in our documentation. This presents an opportunity to both enhance the chatbot's performance and improve the overall clarity and accuracy of our documentation.