With the development of generative artificial intelligence and its practical applications, creating servers for artificial intelligence has become critical for various industries - from automotive manufacturing to medicine, as well as for educational and governmental institutions.
Let's consider the most important components that affect the selection of a server for artificial intelligence: central processing unit (CPU) and graphics processing unit (GPU). Selecting appropriate processors and graphics cards will enable you to set up a high-performance platform and significantly accelerate calculations related to artificial intelligence on a dedicated or virtual (VPS) server.
How do you choose the right processor for your AI server?
The processor is the main "calculator" that receives commands from users and performs "command cycles," which will yield the desired results. Therefore, a big part of what makes an AI server so powerful is its CPU.
You might expect a comparison between AMD and Intel processors. Yes, these two industry leaders are at the forefront of processor manufacturing, with the lineup of Intel 5th generation Intel® Xeon® ( and already announced 6th generation) and AMD EPYC™ 8004/9004 representing the pinnacle of x86-based CISC processors.
If you are looking for excellent performance combined with a mature and proven ecosystem, selecting top-of-the-line products from these chip manufacturers would be the right choice. If budget is a concern, consider older versions of Intel® Xeon® and AMD EPYC™ processors.
Even desktop CPUs from AMD or Nvidia's higher-end models would be a good starting point for working with AI if your workload does not require a large number of cores and multithreading capabilities. In practice, when it comes to language models, the choice of graphics accelerator or the amount of RAM installed in the server will have a greater impact than the choice between CPU types.
While some models, such as the 8x7B from Mixtral, can produce results comparable to the computational power of tensor cores found in video cards when run on a CPU, they also require 2-3 times more RAM than a CPU + GPU bundle. For instance, a model that runs on 16 GB of RAM and 24 GB of GPU video memory may require up to 64 GB of RAM when run solely on the CPU.
In addition to AMD and Intel, there are other options available. These can be solutions based on ARM architecture, such as NVIDIA Grace™, which combines ARM cores with patented NVIDIA features, or Ampere Altra™.
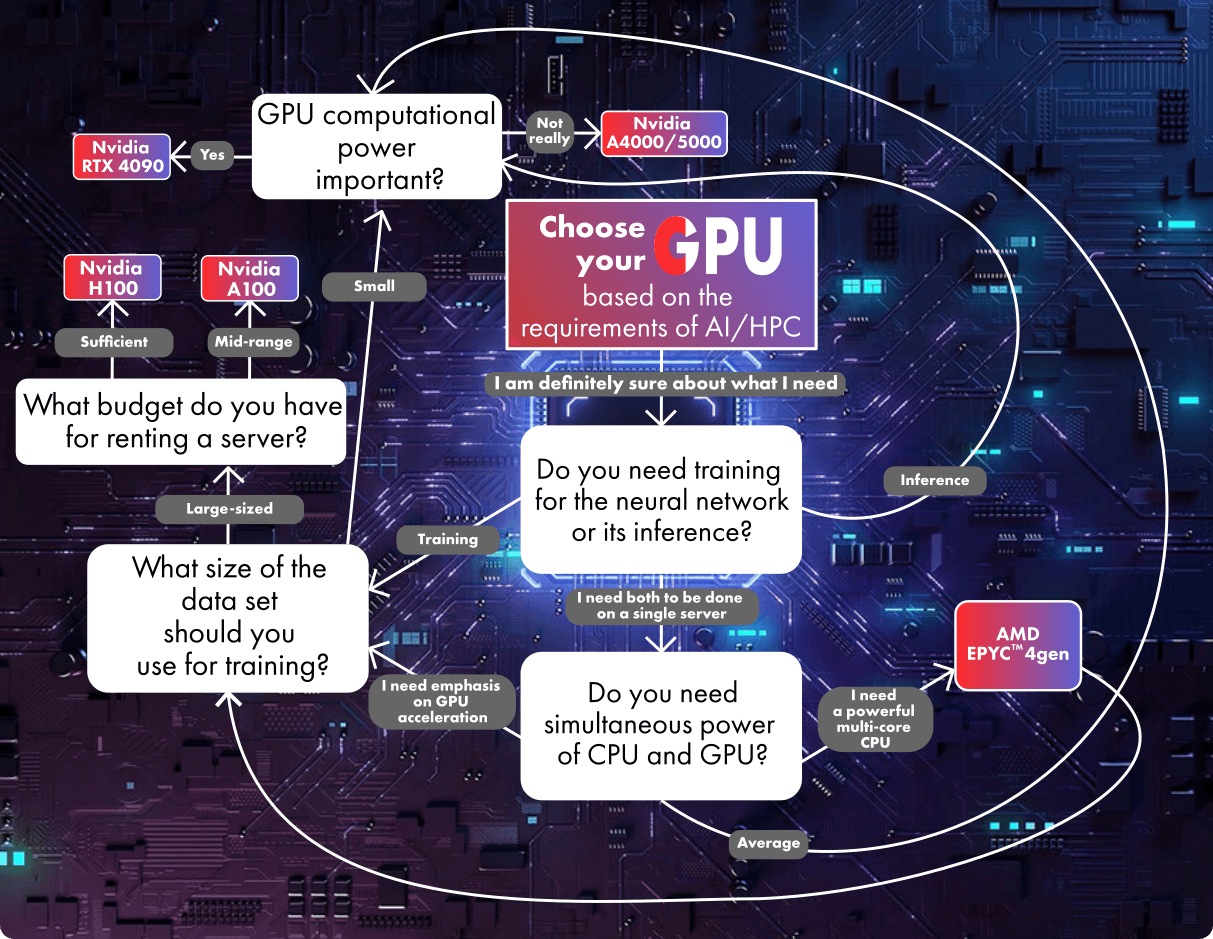
How do you choose the right graphics processing unit (GPU) for your AI server?
The GPU plays an increasingly important role in AI server operations today. It serves as an accelerator that helps the CPU process requests to neural networks much faster and more efficiently. The GPU can break down tasks into smaller segments and perform them simultaneously using parallel computing or specialized cores. For example, NVIDIA's tensor cores provide orders of magnitude higher performance in 8-bit floating-point (FP8) calculations with Transformer Engine, Tensor Float 32 (TF32), and FP16, showing excellent results in high-performance computing (HPC).
This is particularly noticeable not during inference (the operation of the neural network) but during training, as for example, for models with FP32, this process can take several weeks or even months.
To narrow down your search criteria, consider the following questions:
- Will the nature of your AI server's workload change over time? Most modern GPUs are designed for very specific tasks. The architecture of their chips may be suitable for certain areas of AI development or application, and new hardware and software solutions can render previous generations of GPU obsolete in just a few years (1-2-3).
- Will you mainly focus on training AI or inference (usage)? These two processes are the foundation of all modern AI iterations with limited memory budgets.
During training, the AI model processes a large amount of data with billions or even trillions of parameters. It adjusts the "weights" of its algorithms until it can consistently generate correct results.
In inference mode, the AI relies on the "memory" of its training to respond to new input data in the real world. Both processes require significant computational resources, so GPUs and expansion modules are installed for acceleration.
Graphic processing units (GPUs) are designed specifically for training deep learning models with specialized cores and mechanisms that can optimize this process. For example, NVIDIA's H100 with 8 GPU cores provides more than 32 petaflops of performance in FP8 deep learning. Each H100 contains fourth-generation tensor cores using a new type of data called FP8 and "Transformer Engine" for optimization. Recently, NVIDIA introduced the next generation of their GPUs B200, which will be even more powerful.
A strong alternative to AMD solutions is the AMD Instinct™ MI300X. Its feature is a large memory capacity and high data bandwidth, which is important for inferencing-based generative AI applications, such as large language models (LLM). AMD claims that their GPUs are 30% more efficient than NVIDIA's solutions but have less mature software.
If you need to sacrifice a bit of performance to fit within budget constraints or if your dataset for training the AI is not too large, you can consider other options from AMD and NVIDIA. For inferencing tasks or when continuous operation in 24/7 mode for training is not required, "consumer" solutions based on Nvidia RTX 4090 or RTX 3090 may be suitable.
If you are looking for stability in long-term calculations for model training, you can consider NVIDIA's RTX A4000 or A5000 cards. Although the H100 with PCIe bus may offer a more powerful solution with 60-80% performance depending on the tasks, the RTX A5000 is a more accessible option and could be an optimal choice for certain tasks (such as working with models like 8x7B).
For more exotic inference solutions, you can consider cards like AMD Alveo™ V70, NVIDIA A2/L4 Tensor Core, and Qualcomm® Cloud AI 100. In the near future, AMD and NVIDIA plan to outperform Intel's GPU Gaudi 3 on the AI training market.
Considering all these factors and taking into account software optimization for HPC and AI, we recommend servers with Intel Xeon or AMD Epyc processors and GPUs from NVIDIA. For AI inferencing tasks, you can use GPUs from RTX A4000/A5000 to RTX 3090, while for training and working on multi-modal neural networks, it's advisable to allocate budgets for solutions from RTX 4090 to A100/H100.