
Despite massive supply constraints, we were lucky enough to acquire several NVIDIA GeForce RTX 5090 GPUs and benchmarked one. The performance isn't as straightforward as Nvidia's initial promise, but the results are fascinating and promising for utilizing the GPU for AI/model workflows.
Rig Specs
The setup was fairly straightforward: we took a server system with a 4090, removed it, and swapped it out for the 5090. This gave us the following configuration: IntelCore i9-14900K, 128GB of RAM, a 2TB NVMe SSD, and naturally, a GeForce RTX 5090 with 32GB of VRAM.

If you’re thinking "what about those power connectors?", here too everything appears stable—the connector never exceeded 65 degrees Celsius during operation. We're running the cards with the stock air coolers, and the thermal results can be found in the following section.

The card draws considerably more power than the GeForce RTX 4090. Our entire system peaked at 830-watts, so a robust power supply is essential. Thankfully, we had sufficient headroom in our existing PSU, so a replacement wasn't necessary.
AI Platform: GPU Servers with Preconfigured AI and LLM Software
Rent GPU servers featuring professional and gaming graphics cards from NVIDIA for your AI project. Preinstalled software is ready to work immediately upon server deployment.
Software
We'll be running and benchmarking everything within Ubuntu 22.04. The process involves installing the OS, then installing the drivers and CUDA using our magic custom script. Nvidia-smi confirms operation, and our "GPU monster" is pulling enough power to rival entire home power draws. The screenshot displays temperature and power consumption under load, where the CPU is only pegged at 40% utilization.
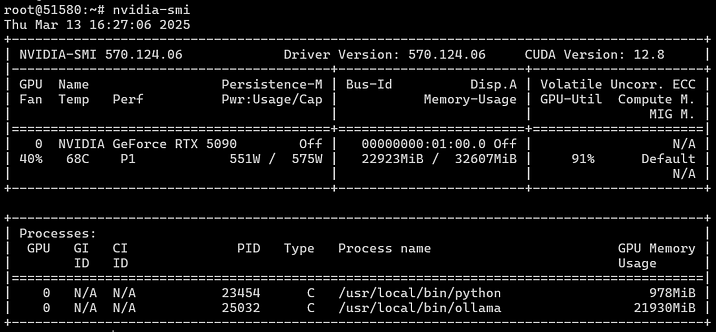
With the OS running, we installed Docker, configured Nvidia GPU passthrough to the containers, and then installed Ollama directly into the OS, and OpenWebUI as a Docker container. Once everything was running, we began our benchmarking suite.
Benchmarking
To kick things off, we decided to evaluate the speed of various neural models. For convenience, we’ve opted to use OpenWebUI alongside Ollama. Let’s get this out of the way, direct usage with Ollama will generally be faster and require fewer resources. However, we can only extract data from our tests through the API, and our objective is to see how much faster the 5090 performs compared to the previous generation (the 4090) and by how much.
The RTX 4090 in the same system served as our control card for comparisons. All tests were performed with pre-loaded models, and the values recorded were averages across ten separate runs.
Let’s start with DeepSeek R1 14B in Q4 format, using a context window size of 32,768 tokens. The model processes thoughts in independent threads and consumes a fair number of resources, but it remains popular for consumer-tier GPUs with less than 16GB of VRAM. This test ensures we eliminate the potential impact from storage, RAM, or CPU speed, as all computations are handled within VRAM.
This model requires 11GB of VRAM to operate.

We used the following prompt: “Write code for a simple Snake game on HTML and JS”. We received roughly 2,000 tokens in output.
| RTX 5090 32 GB | RTX 4090 24 GB | |
| Response Speed (Tokens per Second) | 104,5 | 65,8 |
| Response Time (Seconds) | 20 | 40 |
As evidenced, the 5090 demonstrates performance gains of up to 40%. And this happens even before popular frameworks and libraries have been fully optimized for the Blackwell architecture, although CUDA 12.8 is already leveraging key improvements.
Next Benchmark: We previously mentioned using AI-based translation agents for documentation workflows, so we were keen to see if the 5090 would accelerate our processes.
For this test, we adopted the following system prompt for translating from English to Turkish:
You are native translator from English to Turkish.
I will provide you with text in Markdown format for translation. The text is related to IT.
Follow these instructions:
- Do not change Markdown format.
- Translate text, considering the specific terminology and features.
- Do not provide a description of how and why you made such a translation.
- Keep on English box, panels, menu and submenu names, buttons names and other UX elements in tags '** **' and '\~\~** **\~\~'.
- Use the following Markdown constructs: '!!! warning "Dikkat"', '!!! info "Bilgi"', '!!! note "Not"', '??? example'. Translate 'Password" as 'Şifre'.
- Translate '## Deployment Features' as '## Çalıştırma Özellikleri'.
- Translate 'Documentation and FAQs' as 'Dokümantasyon ve SSS'.
- Translate 'To install this software using the API, follow [these instructions](../../apidocs/index.md#instant-server-ordering-algorithm-with-eqorder_instance).' as 'Bu yazılımı API kullanarak kurmak için [bu talimatları](https://hostkey.com/documentation/apidocs/#instant-server-ordering-algorithm-with-eqorder_instance) izleyin.'We send the content of that documentation page in reply.
| RTX 5090 32 GB | RTX 4090 24 GB | |
| Response Speed (Tokens per Second) | 88 | 55 |
| Response Time (Seconds) | 60 | 100 |
On output, we average 5K tokens out of a total of 10K (as a reminder, our context length is currently set to 32K). As you can see here, 5090 is faster, even within the anticipated 30% improvement range.
Moving on to the “larger” model, we'll take the new Gemma3 27B. For it, we're setting the input context size to 16,384 tokens. And we get that on the 5090, the model consumes 26 GB of V-RAM.

This time, let’s try generating a logo for a server rental company (in case we ever decide to change the old HOSTKEY logo). The prompt will be this: "Design an intricate SVG logo for a server rental company."
Here’s the output:
| RTX 5090 32 GB | RTX 4090 24 GB | |
| Response Speed (Tokens per Second) | 48 | 7 |
| Response Time (Seconds) | 44 | 270 |
A resounding failure for the RTX 4090. Inspecting GPU usage, we see that 17% was consumed by the central processing unit and system memory, guaranteeing a reduced speed. Furthermore, the total resource usage increased because of this. 32 GB of on-VRAM on the RTX 5090 really helps with models of this size.

Gemma3 is a multimodal model, which means it can identify images. We're taking an image and asking it to find all the animals on it: "Find all animals in this picture.” We’re leaving the context size at 16K.
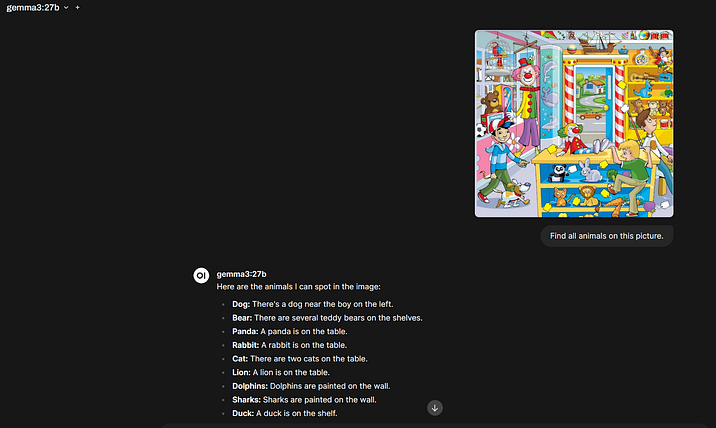
With the 4090, things weren’t as straightforward. With this output context size, the model stalled. Reducing it to 8K lowered video memory consumption, but it appears that processing images on the CPU, even just 5% of the time, isn't the best approach.

Consequently, all results for the 4090 were obtained with a 2K context, giving this graphics card a head start, as Gemma3 only utilized 20 GB of video memory.

For comparison, figures in parentheses show the results obtained for the 5090 with a 2K context.
| RTX 5090 32 GB | RTX 4090 24 GB | |
| Response Speed (Tokens per Second) | 49 (78) | 39 |
| Response Time (Seconds) | 10 (4) | 6 |
Next up for testing is "the ChatGPT killer" again, this time DeepSeek, but with 32 billion parameters. The model occupies 25 GB of video memory on the 5090 and 26 GB, utilizing the CPU partially, on the 4090.


We'll be testing by asking the neural network to write us browser-based Tetrisa. We’re setting the context to 2K, keeping in mind the issues from previous tests. We’re giving it a purposefully uninformative prompt: "Write Tetris in HTML," and waiting for the result. A couple of times, we even get playable results.
| RTX 5090 32 GB | RTX 4090 24 GB | |
| Response Speed (Tokens per Second) | 57 | 17 |
| Response Time (Seconds) | 45 | 180 |
Regarding the Disappointments
The first warning signs sounded when we tried comparing the graphics cards while working with Vector databases: creating embeddings and searching for results considering them. We weren’t able to create a new knowledge base. Afterwards, web search in OpenWebUI didn't work.
Then we decided to check the speed in graphic generation, setting up ComfyUI with the Stable Diffusion 3.5 Medium model. Upon starting generation, we got the following message:
CUDA error: no kernel image is available for execution on the deviceWell, we thought, maybe we have old versions of CUDA (no), or Drivers (no), or PyTorch. I updated the latest to a nightly version, launched it, and got the same message.
We dug into what other users are writing and if there’s a solution, and it turned out the problem was the lack of a PyTorch build for the Blackwell architecture and CUDA 12.8. And there was no solution other than rebuilding everything manually with the necessary keys from source.
Judging by the lamentations, a similar problem exists with other libraries that "tightly" interact with CUDA. You can only wait.
So, the bottom line?
Key findings: Jensen Huang didn’t mislead — in AI applications, the 5090 performs faster, and often significantly faster than the previous generation. The increased memory capacity enables running 27/32B models even with the maximum context size.However, there’s a “but”—32 GB of VRAM is still a bit lacking. Yes, it’s a gaming card, and we’re waiting for professional versions with 64 GB or more of VRAM to replace the A6000 series (the RTX PRO 6000 with 96 GB of VRAM was just announced).
We feel that NVIDIA was a bit miserly here and could easily have included 48 GB in the top-tier model without a major cost impact (or released a 4090 Ti for enthusiasts). Regarding the fact that the software isn’t properly adapted: NVIDIA once again demonstrated that it often “neglects” working with the community, as non-functional PyTorch or TensorFlow at launch (there are similar issues due to the new version of CUDA) is simply humiliating. But that’s what the community is for—to resolve and fairly quickly solve such problems, and we think the software support situation will improve in a couple of weeks.