
Hostkey has decided not to reinvent the wheel but rather to build our system based on Open Distro. In this article, we will discuss an architecture-based solution made possible thanks to the advantageous decision of the AMQP RabbitMQ broker to emphasize fault tolerance and minimal consumption of log data during failures.
In short, the system for processing and storing logs is performed broadly according to the following principle:

The log collection application sends them directly via the SYSLOG protocol to the Logstash data processing pipeline. From there, the data enters the Elasticsearch database and is then used by the Kibana data visualization panel.
All ELK elements support fault tolerance, and the direct interaction scheme is quite stable. However, with the growth of the system, it is necessary to build a linear increase in the power of the log processing system, since Logstash is the point for receiving logs and at the same time a system for parsing them. As the number of messages grows, a linear increase in system performance is required; that is, the receiver should not become “choked” with messages - on the contrary, it should reliably provide information about failures without losing messages. To this end, it is necessary to allocate resources for the expected surges in advance.
In one of our previous articles, we talked about how hardware management works at Hostkey and what role the message broker cluster (RabbitMQ) plays in our infrastructure. A feature of RabbitMQ is high reliability and the ability to process large volumes of messages with minimal resource consumption. This is possible because Rabbit does not process messages, but only stores and delivers them.
We decided to refine the processing system and add RabbitMQ as a queue buffer.

This solution allowed us to increase the system fault tolerance: if something goes critically wrong during the processing and storage of logs, they are returned to Rabbit AMQP. Another advantage of our solution is the additional flexibility in working with logs - for example, we can include additional analyzers and perform analogical actions to manage actions and process logs.
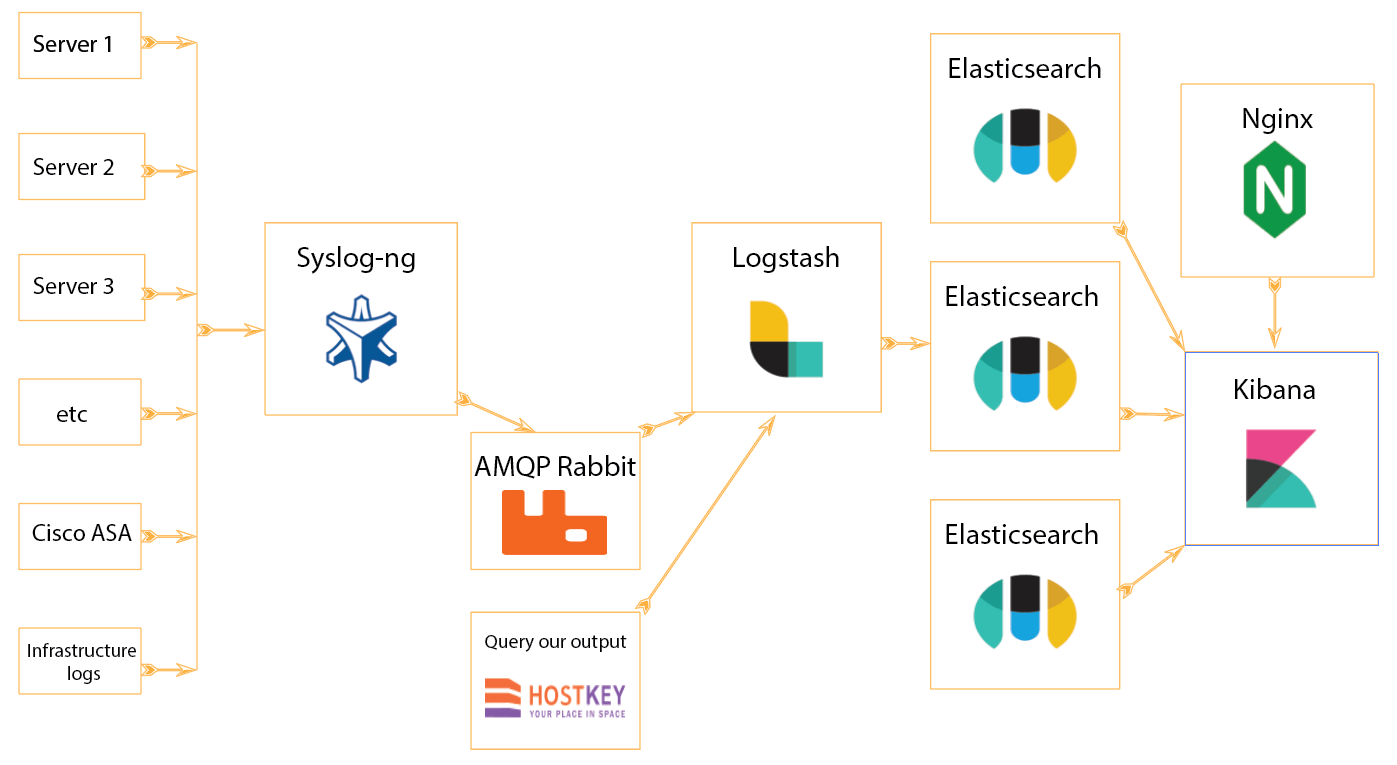
* We use Nginx to proxy Kibana
As a result, Logstash pulls information from output queues as it allows you to process messages. Rabbit plays the role of a cache here, it is able to accept many times more information than Logstash.
In case of emergency, you can also view messages through Rabbit. Furthermore, Rabbit also monitors the accumulation of messages in queues, enabling the direct identification of significant (surge in the number of logs) or release (failure of the ELK system) problems in the infrastructure.
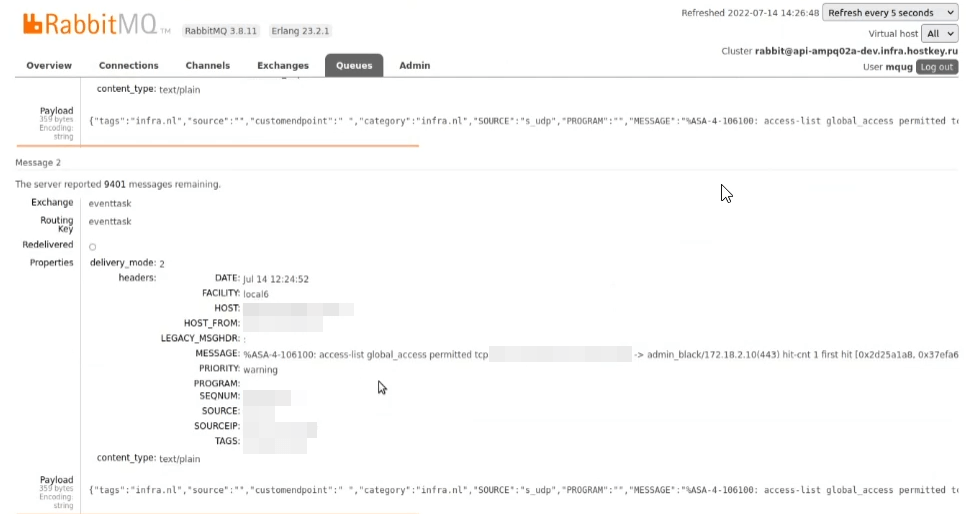
Logstash client agent configuration:
destination d_ampqp {
amqp(
vhost("/")
host("HOST_IP")
port(5672)
exchange("****")
exchange-type("direct")
routing-key("****")
body("$(format-json —-scope nv_pairs —-pair category=\"infra.ru\" —-pair
source=$source —-pair customendpoint=\" \" —-pair tags=\"infra.ru\")")
persistent(yes)
username("")
password("")
}
}Logstash indexer agent configuration:
input {
rabbitmq {
host => "HOST_IP"
queue => "syslog"
heartbeat => 30
durable => true
password => "****"
user => "****"
}
}
filter {
# your filters here
}
output {
elasticsearch { hosts => ["https://localhost:9200"]
hosts => "https://localhost:9200"
manage_template => false
user => "admin"
password => "****"
ssl => false
ssl_certificate_verification => false
index => "%{[@metadata][syslog]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}System Clients
Having gone over the general idea, let's now move on to its implementation. Firstly, we split the client log collection system into trusted and untrusted. Trusted applications / hosts have the ability to log in and write to the message queue (directly or through an intermediary, which we will talk about a little later). Untrusted applications are those that do not have direct access to RabbitMQ.
Let's explain with an example:
- A trusted client is a company's standard infrastructure host.
- An untrusted client is a LiveCD that installs the OS on the client host (the client can potentially interfere with the process and gain access to the RabbitMQ infrastructure).
Onwards, it was necessary to resolve the issue of a transparent (for applications) transition from the syslog protocol to AMQP. syslog-ng is great for converting syslog traffic to AMQP. Our main operating systems used in the infrastructure are CentOS7 and 8. For the seventh version of the OS, we need to build a package with an updated version of the server since the version from the regular repository does not support AMQP. There is no such problem with 8. Next, on infrastructure (trusted) installations, one must replace the standard rsyslog with syslog-ng and configure its interaction with the Rabbit cluster:
destination d_ampqp {
amqp(
vhost("/")
host("AMQP_HOST")
port(5672)
exchange("eventtask")
exchange-type("direct")
routing-key("eventtask")
body("$(format-json —-scope core)")
persistent(yes)
username("RABBIT_USERNAME")
password("RABBIT_PASSWORD")
);
};For untrusted hosts or hosts on which syslog-ng cannot be installed, an external syslog-ng receiver is required.
We decided to place such a receiver directly in the RabbitMQ hosts to minimize unnecessary service traffic, but this is not a rule - a group of syslog-ng hosts may well work separate from the broker. We made the number of receivers equal to the number of hosts in the Rabbit cluster, and the choice of the host is carried out through DNS-RoundRobin. This scheme has the disadvantage of a possible loss of messages in case of failure of one of the hosts, but the problem is solved quite easily by moving the receiver hosts to a clustered IP via a pacemaker / corosync bundle (this is an easy-to-use mechanism that we can talk about in a separate article).
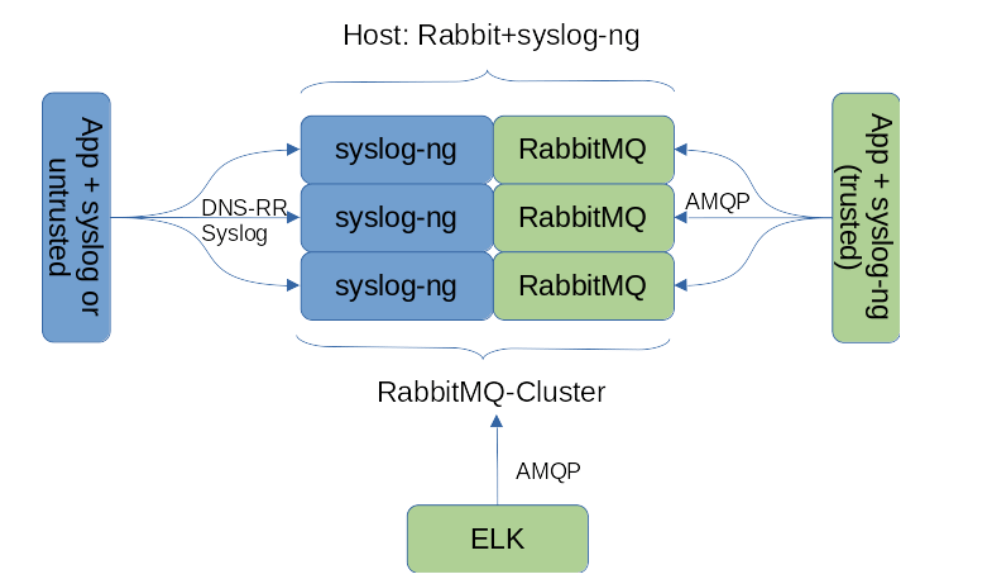
Benefits of the final system:
- Fault tolerance - the system is able to process large message flows without loss and withstands the failure of any individual host providing service.
- Flexibility - system performance is easy to scale, and the system is able to receive messages from any syslog client: from advanced (syslog-ng) to the most conservative (Microsoft, etc).
- Profitability - the system allows you to avoid dedicating excess resources to processing logs. A "flurry" of messages does not lead to their loss.