
With the release of the new Blackwell chip generation for the consumer GPU market, it was expected to see workstation versions of the GPU as well — versions intended to replace the A5000/A6000 series and priced lower than A100/H100-level GPUs.
This did happen, but in the process, NVIDIA completely confused everyone by launching no fewer than three versions of the RTX PRO 6000 Blackwell in just six months. We at HOSTKEY joined the performance race with the release of the latest version — the RTX PRO 6000 Blackwell Server Edition — tested it thoroughly, and we have some results to share (and show).
* - The GPU is provided for a free trial on an individual basis and is not available in all cases.
What are you?
If you look at the official GPU specifications on the Nvidia website, we see the following picture:
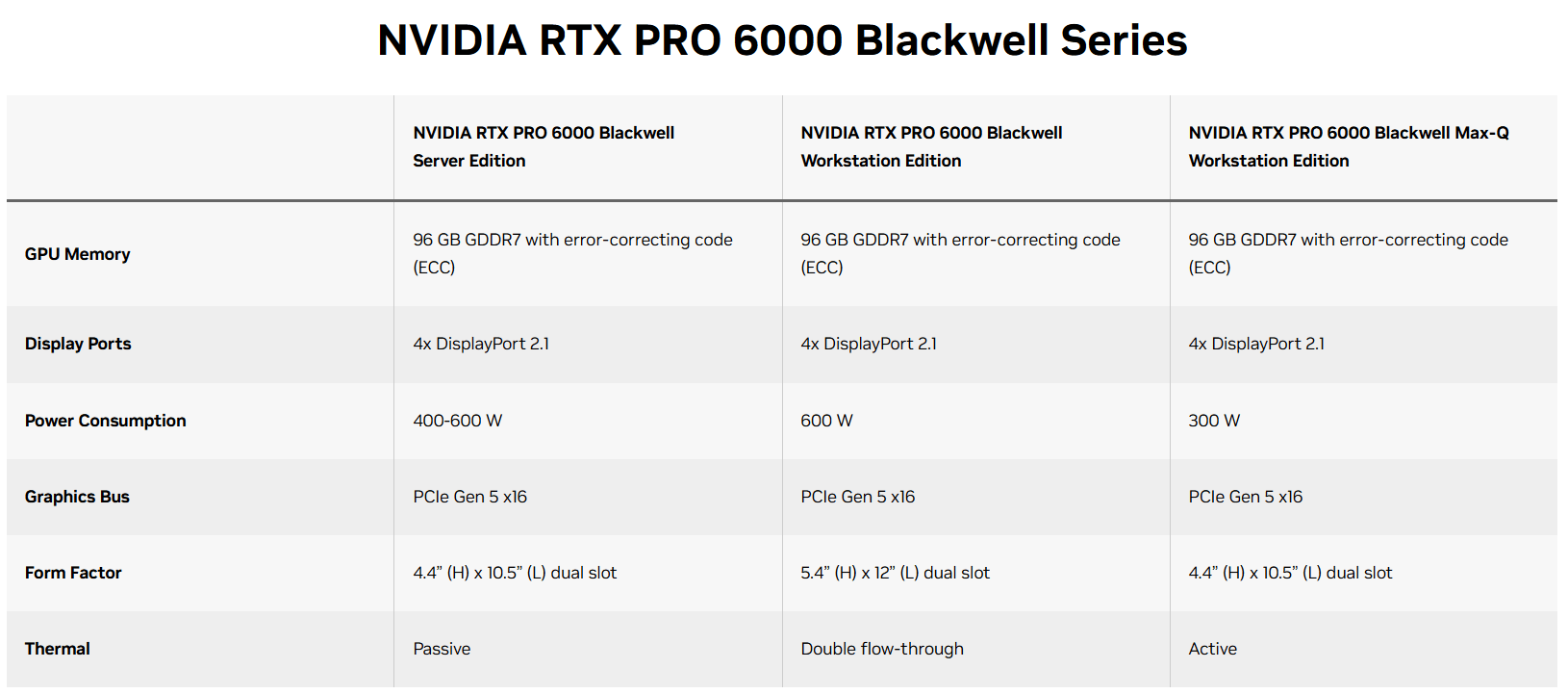
We have three video card options that differ in form factor, cooling system type, and maximum power consumption. At first glance, one might assume that the middle version (Workstation Edition) should be the fastest and likely the hottest, based on its power consumption. Let's compare their specifications in more detail and contrast them with the fastest RTX 5090D.
| Workstation Edition | Max-Q Workstation edition | Server Edition | RTX 5090 | |
| CUDA Parallel Processing cores | 24064 | 24064 | 24064 | 21760 |
| Single-Precision Performance (FP32) | 125 TFLOPS | 125 TFLOPS | 120 TFLOPS | 103 TFLOPS |
| RT Core Performance | 380 TFLOPS | 333 TFLOPS | 355 TFLOPS | - |
| Memory Bandwidth | 1792 GB/s | 1792 GB/s | 1597 GB/s | 1792 GB/sec |
| GPU Memory | 96 GB GDDR7 with ECC | 96 GB GDDR7 with ECC | 96 GB GDDR7 with ECC | 32 GB GDDR7 |
| Memory Interface | 512-bit | 512-bit | 512-bit | 512-bit |
| Power Consumption | Up to 600W (Configurable) | 300W | 600W | 575W |
The GPU we tested (RTX 6000 Blackwell Server Edition) is the weakest in the lineup (although one might expect the Server version to be more powerful than the Workstation edition), yet it still outperforms the consumer-grade RTX 5090 due to a higher core count on the chip. Thanks to reduced clock speeds, the card's power consumption remains within 300W, but it can be toggled into boost mode, where it operates at frequencies close to those of the Workstation Edition. In 300W mode, the card runs cooler than the RTX 5090, but when boosted, it surpasses the consumer version in performance.

The main feature of the Server Edition is its passive cooling, which utilizes the standard airflow of the server chassis. Thanks to its compact size, it allows for the simultaneous placement of a large number of GPUs in a row (photo from the exhibition).

Assembling the Server
We will test this GPU using the following configuration:
- Server platform from ASUS
- AMD EPYC 9554 processor
- 768 GB DDR5 RAM
- 2 x 3.84 TB NVMe
- 1 x RTX 6000 PRO SERVER
Technically, the platform supports up to 4 GPUs, but due to power consumption limitations in the no-power-restriction mode, a maximum of two RTX 6000 PRO SERVER GPUs can be installed. The issue arises because the platform provides 4 power connectors per side, which are connected to the card via an adapter. As shown in the photo, the case is equipped with powerful fans on both sides and a specialized housing, ensuring excellent airflow over the radiators and GPU components.


Now, onto the tests
We'll conduct the tests in two modes: running LLMs using the Ollama + OpenWebUI setup and video generation with the free WAN2 model in ComfyUI. More precisely, we'll use our neural network assistant, which employs multiple models for RAG (Retrieval-Augmented Generation) and interacts with an external MCP server. The LLM under test is Qwen3-14B, which requires approximately 14 GB of VRAM in 16K context mode.
Looking ahead, we can say that comparisons involving models fully fitting into the GPU show a performance increase of around 15–20% over the RTX 5090. Therefore, we'll present results relative to other GPUs rather than using the RTX 5090 as a baseline.
To start, we'll compare the previous generation A5000 with the RTX 6000 PRO. The comparison will be conducted in low power consumption mode, where the GPU actually consumes up to 450W (boost mode), rather than the 300W maximum stated in the documentation. Recall that the A5000 features 24 GB of GDDR6 VRAM.
We'll ask our neural network assistant the following question: "Hi. How to install Nvidia drivers on Linux?"
| GPU | Response Speed, Tokens per Second | Response Speed, Tokens per Second | Response Speed, Tokens per Second |
| A5000 (Cold Boot) | 47.3 | 2700 | 17 |
| RTX 6000 PRO (Cold Boot) | 103.5 | 8285 | 5 |
| A5000 (Model Already Loaded to GPU) | 48.2 | 2910 | 13 |
| RTX 6000 PRO (Model Already Loaded to GPU) | 107 | 11000 | 4 |
As you can see, compared to the A5000, which is still in use, the new GPU is over two times more powerful, and its response speed (i.e., switching between models, searching, querying the MCP server, processing, and generating responses) is more than three times faster.
However, using the RTX 6000 PRO for such tasks is like cracking nuts with a microscope. For comparison, let’s test the same workload on the H100 in a "hot run" (with the model already loaded). The H100 has 3.5 times fewer CUDA cores, lower clock speeds, and theoretical performance roughly 4 times lower in synthetic benchmarks compared to the RTX 6000 PRO. However, it benefits from a 4nm process node (vs. 5nm for the RTX 6000 PRO), 10 times greater memory bandwidth, and a more advanced memory type. Despite this, our version of the H100 has 80 GB of memory, compared to the H100’s 96 GB.
| GPU | Response Speed, Tokens per Second | Response Speed, Tokens per Second | Response Speed, Tokens per Second |
| H100 (Model Already Loaded to GPU) | 60 | 2900 | 4 |
| RTX 6000 PRO (Model Already Loaded to GPU) | 107 | 11000 | 4 |
Despite the RTX 6000 PRO’s nearly twofold advantage in tokenization speed, the overall performance of both GPUs is on par. This makes the RTX 6000 PRO an excellent replacement for the A100/H100 in server inference workloads, considering that HBM3’s bandwidth during data transfers lags behind GDDR7. However, for model training or fine-tuning, the H100 excels due to its reduced power consumption, hardware-level support via the Transformer Engine for models with FP16/FP8 precision (the H100 supports only FP4), and its ability to accelerate tasks when models are fully loaded into memory (with bandwidth up to 3 TB/s).
Putting the RTX 6000 PRO to Full Use
Much more interesting is to test this GPU in another resource-intensive task—specifically, video generation. For this, we'll use a new model from Alibaba with open weights and install everything in ComfyUI. Again, we've encountered a problem: CUDA 12.9 (and later versions) and its compatibility with PyTorch. The solution, once again, is to install from nightly builds until official support is available:
pip install --pre --upgrade --no-cache-dir torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cu129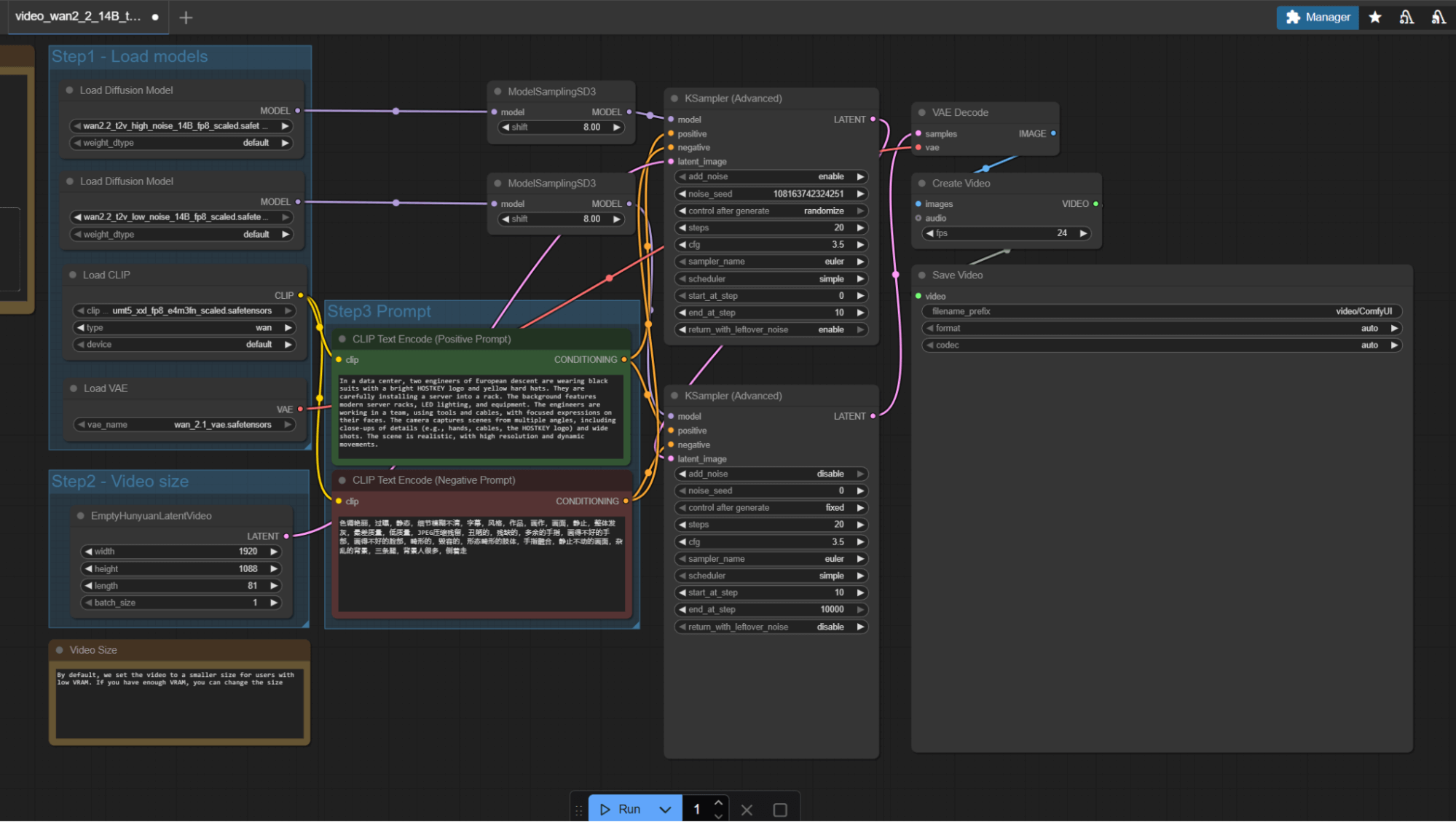
The process involves using the video generation mode based on prompts (Wan 2.2 14B text to video), which operates as follows:
A whimsical and humorous scene unfolds on a serene riverbank, where two hardworking beavers in bright yellow safety helmets and rugged orange overalls team up to haul a massive, gleaming server rack toward their meticulously built beaver lodge. The lodge, constructed from logs and stones, features a bold, modern sign reading "HOSTKEY" in bold, tech-inspired typography. The beavers’ determined expressions and the server rack’s glowing lights create a surreal blend of nature and technology. The river sparkles in the sunlight, and the lodge’s entrance is framed by lush greenery, emphasizing the harmony between the beavers’ natural habitat and their unexpected tech-savvy mission. The scene is vibrant, detailed, and filled with playful energy, blending the charm of wildlife with the precision of data infrastructure. Perfect for a lighthearted, tech-themed animation or meme.Launching the process takes approximately 40 minutes. Memory usage and power consumption during peak performance are visible in the screenshot below. The maximum temperature never exceeded 83 degrees. The generation is set to 720p/24, as the model is optimized for this resolution. Setting it to 1080p or increasing the frame rate may cause the GPU to freeze or significantly extend the generation time beyond two hours (we didn’t wait longer, as the process became stuck at 60%).
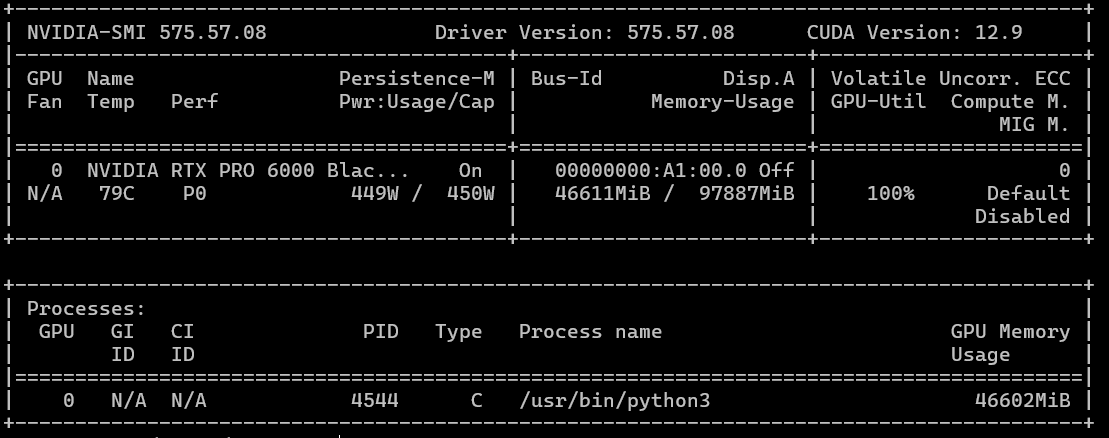

If we were to use the WAN 2.2 5B model instead, generating a similar video (5 seconds, 24 frames) takes just 160 seconds.
Enhancing Power
As previously mentioned, the GPU features a power consumption mode switch. While this setting didn’t significantly benefit the models, switching to a 600-watt power mode already yields improved results. According to nvidia-smi readings, we managed to extract an additional five watts of performance from the GPU. However, in this mode, temperatures may spike up to 90 degrees.
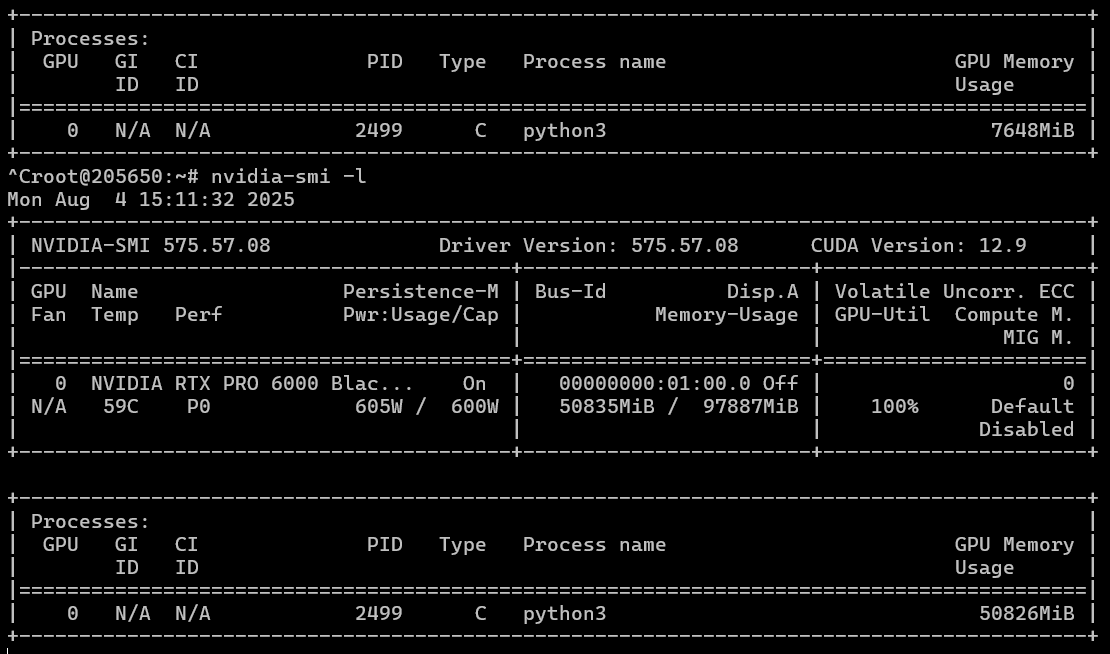
On average, power consumption in both modes during generation remains within the 200–250 watt range.
As evident, increasing the maximum power consumption accelerates the generation by 25%, reducing it to an average of 30 minutes. However, this comes at the cost of significantly higher chip and component temperatures. For tasks requiring prolonged GPU operation under heavy load, it’s advisable to keep the system in low-power consumption mode to avoid thermal stress.

Conclusion
The GPU has proven to be impressive. It is far more stable than the consumer-grade 5090, lacks the dust-prone fans often found on consumer models, features superior memory with parity control, and offers higher clock speeds.
Compared to the H100, it is four times more affordable while delivering comparable (and in some cases even better) performance for tasks unrelated to deep neural network training. Inference, graphics processing, and video handling are significantly faster than in previous generations, and the new CUDA 13 alongside the latest 580 driver version further boosted performance.
A key limitation is the lack of drivers (as of the time of writing) for the Server Edition of Windows. While drivers are available for the Workstation Edition, installation attempts result in a message stating that the GPU is not detected. This issue does not occur in Linux, where we successfully tested the card on both Ubuntu 22.04 and 24.04. However, the drivers required the linux kernel version 6+ and GCC 12 for compilation.
* - The GPU is provided for a free trial on an individual basis and is not available in all cases.