Stable Diffusion WebUI 安装¶
在这篇文章中
Stable Diffusion WebUI(前身为 Automatic1111)是一个用于处理 Stable Diffusion 模型的图形界面,该模型可根据文本描述(提示词)生成图像。Stable Diffusion WebUI 提供了带有按钮、输入字段和设置的直观界面,简化了图像生成过程,无需使用命令行。它允许您轻松更改参数、保存和加载图像,并使 Stable Diffusion 对广大用户(包括不熟悉命令行的用户)变得易于使用。
在 Ubuntu 服务器上安装 Stable Diffusion WebUI¶
警告
Stable Diffusion WebUI 仅在配备 A4000 及以上型号且带有 Tensor 核心的 Nvidia 显卡的 vGPU/GPU 服务器上才能以可接受的性能运行。请确保您已 预安装 Nvidia 驱动程序和 CUDA。
-
以 root 身份通过 ssh 或其他方式登录服务器。
-
安装依赖项:
-
创建
sd用户: -
切换到用户的主目录并切换用户:
-
下载安装脚本:
-
安装 Web 界面:
-
添加启动参数:
- 若要启动可通过服务器 IP 地址访问的图形界面:
echo 'export COMMANDLINE_ARGS="--autolaunch --no-half-vae --xformers --medvram-sdxl --opt-sdp-attention --listen"' >> /home/sd/stable-diffusion-webui/webui-user.sh- 若要启动不带图形界面但配合 OpenWebUI 使用:
echo 'export COMMANDLINE_ARGS="--autolaunch --no-half-vae --xformers --medvram-sdxl --opt-sdp-attention --nowebui --api --api-auth username:password"' >> /home/sd/stable-diffusion-webui/webui-user.sh其中
username:password是访问 API 的用户名和密码。备注
如果服务器上没有人会访问此 API,则可能无需指定
--api-auth username:password参数。 -
下载 SDXL 模型:
-
创建 systemd 服务以实现自动启动:
-
启动服务:
备注
您可以使用命令
sudo service start sdwebui和sudo service stop sdwebui管理 Stable Diffusion WebUI 服务。 -
检查服务状态:
使用 Stable Diffusion WebUI 图形界面¶
要访问图形界面,请使用地址 http://<YOUR_SERVER_IP>:7860。
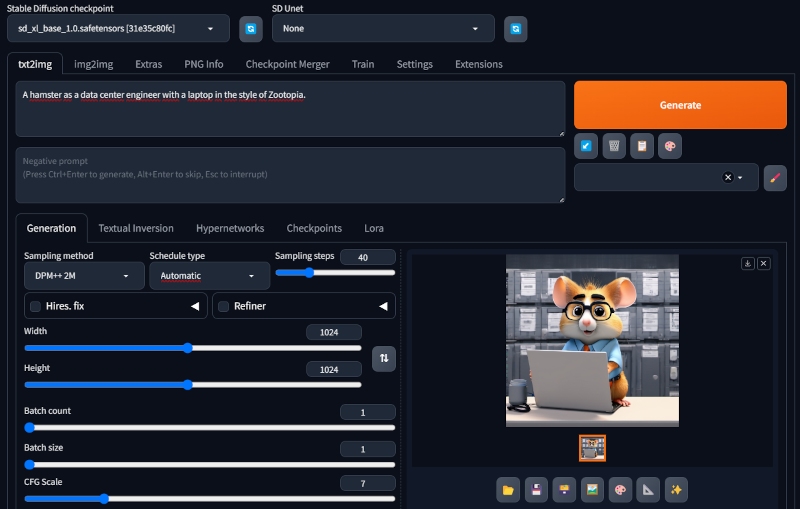
在界面中,设置以下图像生成参数:
- Stable Diffusion 检查点:
sd_xl_base_1.0.safetensors; - 宽度:
1024; - 高度:
1024; - 采样步数:从
30到50。
备注
生成的图像保存在 ~/stable-diffusion-webui/outputs/txt2img-images 目录中,并按创建日期排序。
在 AI 聊天机器人中使用 Stable Diffusion WebUI¶
在 AI 聊天机器人中设置图像生成¶
要在 AI 聊天机器人(OpenWebUI)中启用图像生成,请按照以下步骤操作:
- 以管理员身份登录 AI 聊天机器人;
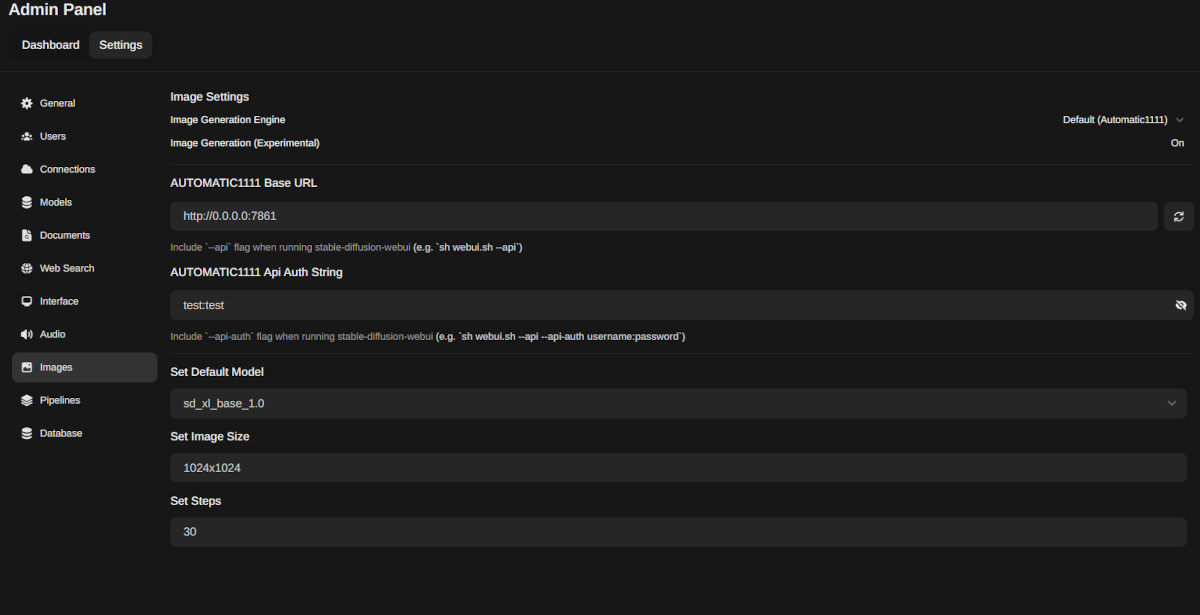
- 进入菜单 Admin Name >> Admin Panel >> Settings >> Images;
- 在 AUTOMATIC1111 Base URL 字段中输入值
http://0.0.0.0:7860,并在 AUTOMATIC1111 Api Auth String 字段中输入之前设置的username:password; - 之后,将 Image Generation (Experimental) 选项设置为
On; - 选择 Stable Diffusion checkpoint 模型
sd_xl_base_1.0.safetensors; - 将 Set Image Size 参数更改为
1024x1024,并将 Set Steps 值设置为30到50之间; - 点击
Save按钮保存更改。
在 AI 聊天机器人中生成图像的说明¶
要生成图像,请按照以下步骤操作:
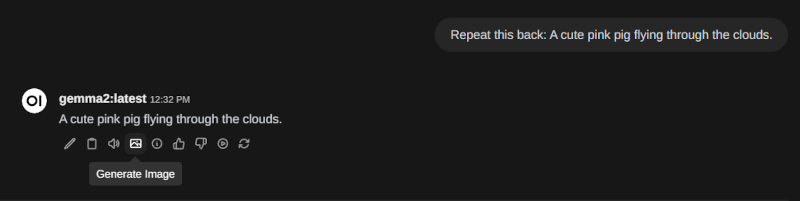
- 选择任意模型,并在聊天机器人的输入字段中发送命令
Repeat this back: <you prompt for image generation>; - 在聊天机器人的响应中,点击 Generate Image 图标;
- 等待结果,耗时 20 到 50 秒,具体取决于服务器的负载。
警告
要生成新图像,请重复步骤 1-4。点击 Regenerate 图标将用新图像替换显示的图像,而不会保存旧图像。
备注
所有生成的图像都保存在服务器的 /var/lib/docker/volumes/open-webui/_data/cache/image/generations/ 目录中。
向 Stable Diffusion OpenWebUI 添加其他模型¶
您可以自行添加任何支持的 .safetensors 和 LORA 格式的模型。为此,您需要通过 SSH 登录服务器,使用以下命令切换到 SD 用户
并使用下面提供的命令下载模型。
警告
安装模型后,请务必使用命令 sudo systemctl restart sdwebui 重启 Stable Diffusion WebUI。
我们建议使用以下模型:
- UI Icons: 用于绘制单色格式图标的模型。
wget -O ~/stable-diffusion-webui/models/Stable-diffusion/uiIcons_v10.safetensors https://civitai.com/api/download/models/367044
所需设置:
- Stable Diffusion 检查点:`uiIcons_v10.safetensors`;
- 宽度:`256`;
- 高度:`256`;
- 采样步数:`30`。
- Deliberate v6: 基于 SD 1.5 的快速模型,可用于图像生成和修复,或配合 ControlNet 在 image2image 模式下进行风格迁移或基于草图的图像生成。
wget https://huggingface.co/XpucT/Deliberate/resolve/main/Deliberate_v6.safetensors -O ~/stable-diffusion-webui/models/Stable-diffusion/Deliberate_v6.safetensors
所需设置:
- Stable Diffusion 检查点:`Deliberate_v6.safetensors`;
- 宽度:`512`;
- 高度:`512`;
- 采样步数:`30` 到 `50`。