ComfyUI¶
在这篇文章中
信息
ComfyUI 是一个专为使用机器学习模型创建图像生成工作流而设计的用户界面。它提供了一个基于节点的可视化编程环境,允许用户在无需编写代码的情况下构建复杂的图像处理管道。
ComfyUI:主要功能¶
- 可视化编程: 直观的基于节点的界面,用于构建复杂的图像生成工作流。
- 模型支持: 兼容广泛的图像生成模型,包括各种版本的 Stable Diffusion。
- 可扩展性: 能够添加自定义节点并集成您自己的模型或算法。
- 参数控制: 对生成参数进行精确控制,包括图像尺寸、步数、采样方法等。
- img2img 和 Inpainting 支持: 利用现有图像作为图像生成的基础或蒙版。
- CUDA 集成: 优化 GPU 利用率以加速生成过程。
- 工作流保存与加载: 保存复杂配置以供重用或分享。
- Flux 集成: 通过 Flux 自动化工作流管理和任务编排。
- 活跃的社区: 定期更新,提供大量社区创建的节点和扩展。
- 本地执行: 所有计算均在本地执行,确保数据隐私和控制权。
配备 ComfyUI 的私有服务器提供高性能、对生成过程的完全控制以及数据保密性。
部署功能¶
| ID | 软件名称 | 兼容操作系统 | 虚拟机 | 物理机 | vGPU | GPU | 最低CPU(核) | 最低内存(GB) | 最低硬盘(GB) | 自定义域名 | 是否启用 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 213 | ComfyUI | Ubuntu 22.04 | - | - | + | + | 4 | 16 | 240 | 否 | 订购 |
- 安装时间:包括操作系统设置在内,需 20-40 分钟;
- 安装 Python、ComfyUI、CUDA、NVIDIA 驱动程序和 Flux;
- 系统要求:专业级显卡(NVIDIA RTX A4000/A5000, NVIDIA A100),至少 16 GB 内存。
-
所有模型均存储在
/root/ComfyUI/models/目录下的特定子目录中:checkpoints/:主要 Stable Diffusion 模型;loras/:LoRA 模型;vae/:VAE 模型;controlnet/:ControlNet 模型;upscale_models/:图像超分辨率模型;embeddings/:文本反转嵌入;hypernetworks/:超网络。
-
要添加新模型,请将模型文件复制到相应的目录并重启 ComfyUI。
备注
除非另有说明,默认情况下,我们从开发者网站或操作系统存储库安装软件的最新发布版本。
ComfyUI 部署后的入门指南¶
您的订单付款后,您将收到一封发送至注册时提供的电子邮件地址的通知,告知您的服务器已准备就绪。该通知将包含 VPS IP 地址以及连接所需的登录凭据。我们的客户通过 服务器管理面板和 API — Invapi 管理其设备。
认证数据可在服务器管理面板的 Configuration >> Tags 选项卡或您收到的电子邮件中找到,包括:
- 访问 ComfyUI Web 界面的链接:位于 webpanel 标签中;
- 登录名:
root- 用于管理员; - 密码:在服务器交付时发送至您的电子邮件地址。
连接与初始设置¶
点击 webpanel 标签中的链接后,您将进入 ComfyUI 工作区:
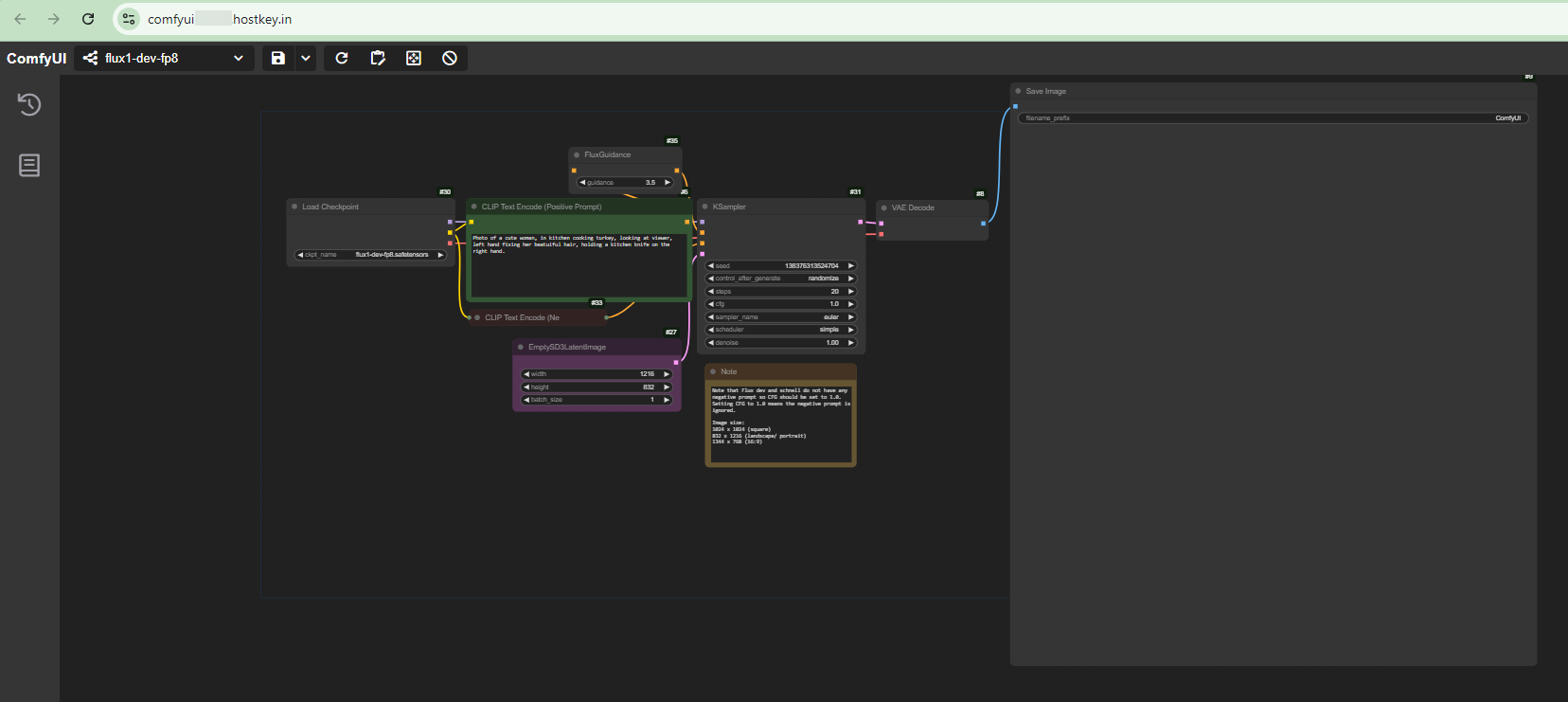
工作区是一个图形界面,主要控制元素显示为相互连接的节点。顶部区域包含工具栏,右侧有 "Unsaved Workflow" 下拉菜单和 "Queue" 按钮。
关键工作元素包括:
- Load Checkpoint 节点,用于加载模型的检查点;
- 两个 CLIP Text Encode 节点,用于输入文本提示,您可以在其中指定所需的图像描述和不需要的元素;
- KSampler 节点,包含生成设置,包括:
- seed(生成种子);
- number of steps(步数);
- prompt following strength(cfg);
- sampler type(euler);
- scheduler;
- noise level(denoise);
- Empty Latent Image 节点,用于设置输出图像分辨率(512x512 像素);
- VAE Decode 和 Save Image 节点,用于最终处理和保存结果。
所有节点通过彩色线条连接,指示图像生成期间的数据流路径。每个节点都可以通过修改其界面参数进行配置。此界面允许您通过连接不同的功能块并为处理的每个阶段设置参数,以可视化的方式构建和配置图像生成过程。
要向工作区添加新节点,请在任意位置右键单击,然后从上下文菜单中选择所需的节点。节点按类别组织,便于搜索:
ComfyUI 界面左下角的 (Gear) 按钮打开 Settings 窗口,其中包含所有主要应用程序设置。
生成图像¶
选择工作流¶
访问 ComfyUI Web 界面后,在菜单左上角的 Workflow 中,从下拉列表中选择 Flux 模型 (flux1-dev-fp8) 的配置:
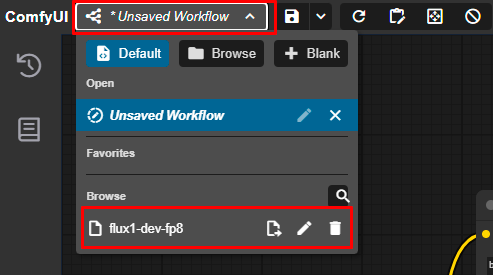
加载的工作流将自动配置所有必要的节点和参数。
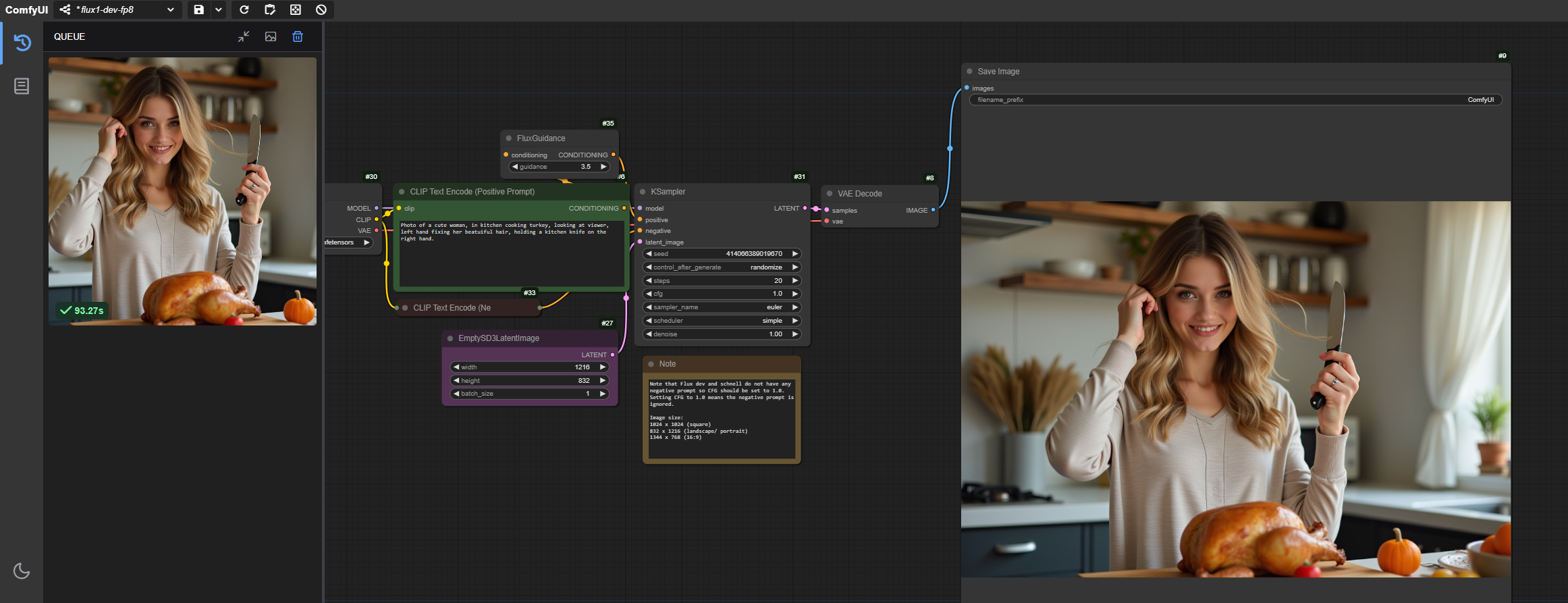
要生成图像,请在 CLIP Text Encode (Positive Promt) 字段中输入提示,然后点击 Queue 按钮:
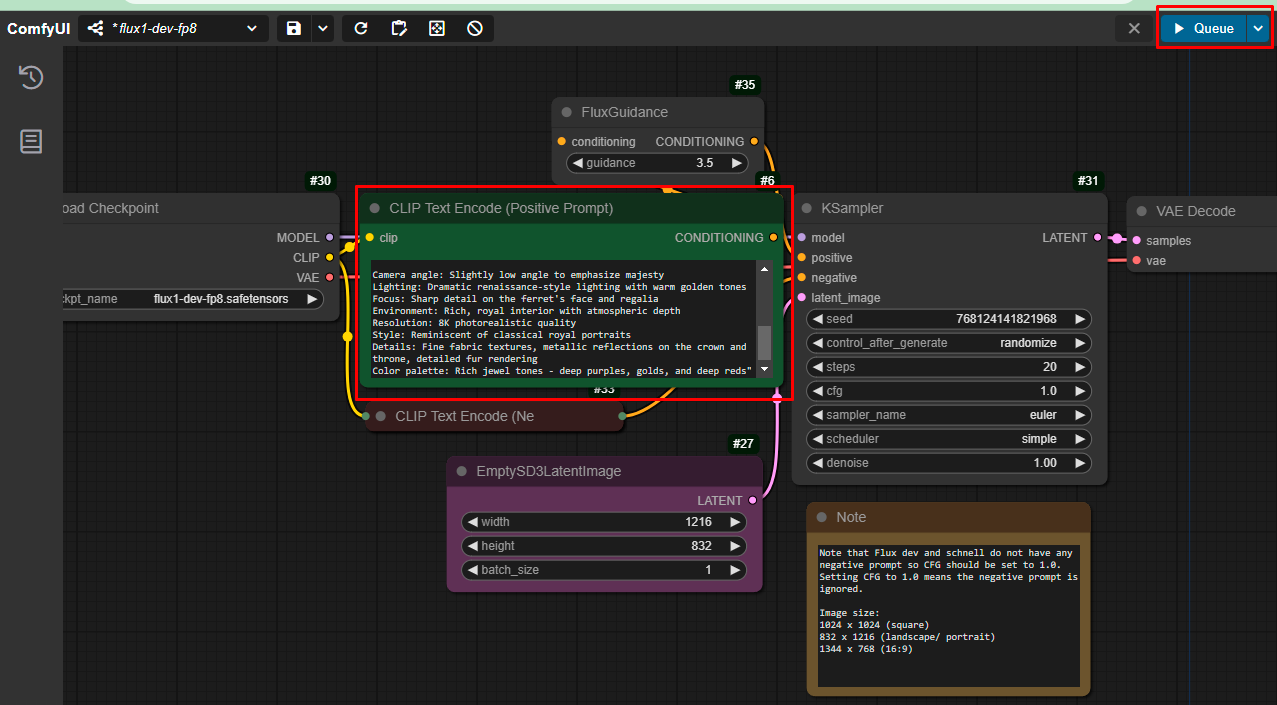
如果配置正确,您将在 ComfyUI 界面中看到生成的图像:
备注
有关使用 ComfyUI 的详细信息,请参阅 官方项目文档。
安装 Stable Diffusion 3.5 Medium 模型¶
SD 3.5 Medium 模型可以在任何带有 RTX 和 16+ GB 显存的 Nvidia vGPU 上运行(A4000, A5000, A6000, A100, H100, 4090)。
操作步骤如下:
-
通过 SSH 以 root 身份登录您的 ComfyUI 服务器,并使用以下命令导航到
/root/ComfyUI/models/checkpoints目录: -
下载带有集成编码器的 SD 3.5 Medium 模型:
-
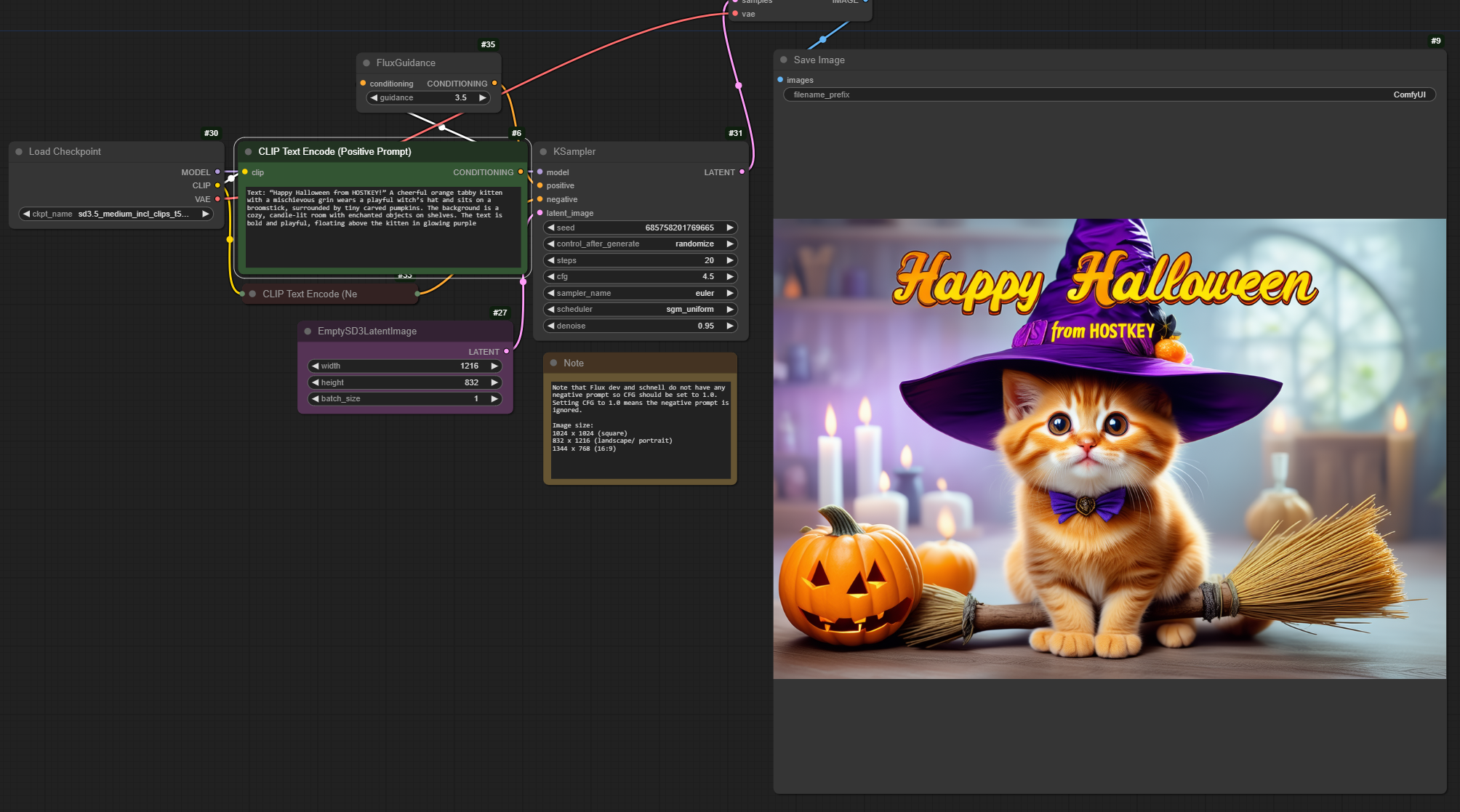
登录 ComfyUI Web 界面,使用与 Flux 模型默认提供的相同工作流,在 Load Checkpoint 块中选择 sd3.5_medium_incl_clips_t5xxlfp8scaled.safetensors 模型,并将 KSampler 块中的值更改为:
- cfg = 4.5
- scheduler = sgm_uniform
- denoise = 0.95
备注
您可以自行下载工作流 链接,并将其 JSON 文件“拖放”到浏览器中打开的 ComfyUI 中。
此后,您可以使用新模型生成图像。
使用 API 订购配备 ComfyUI 的服务器¶
要使用 API 安装此软件,请遵循 这些说明。