Llama-3.3-70B¶
在这篇文章中
信息
Llama-3.3-70B 是一款拥有 700 亿参数的高性能语言模型,可通过 Ollama 进行本地部署。该模型需要强大的计算资源,至少需要 53 GB 的显存(NVIDIA A100/H100 或多张消费级 GPU)。在 Ubuntu 22.04 上的部署支持分布式计算以及与 Open Web UI 的集成,提供完整的数据控制和性能优化。
Llama-3.3-70B 的主要功能¶
-
高性能架构:该模型拥有 700 亿参数,并通过现代分布式计算技术针对处理复杂任务进行了优化,具有无与伦比的准确性;
-
与 Open Web UI 集成:提供位于 8080 端口的现代化 Web 界面,确保对数据、计算资源和处理流程的完全控制;
-
分布式计算:高级支持多卡配置,并在多个 GPU 之间自动负载均衡;
-
可扩展性:能够通过添加额外的 GPU 进行水平扩展以提高性能;
-
性能:使用 LLAMA_FLASH_ATTENTION 技术优化计算并加速请求处理;
-
容错能力:自动恢复系统确保持续运行。
-
使用示例:
-
客户支持:自动化响应用户查询;
-
教育:创建教育材料,辅助解决问题;
-
营销:生成广告文案,分析评论;
-
软件开发:创建和编写代码文档。
-
部署功能¶
| ID | 软件名称 | 兼容操作系统 | 虚拟机 | 物理机 | vGPU | GPU | 最低CPU(核) | 最低内存(GB) | 最低硬盘(GB) | 自定义域名 | 是否启用 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 253 | Llama-3.3-70B | Ubuntu 22.04 | - | - | + | + | 4 | 64 | - | 否 | 订购 |
-
安装时间为 15-30 分钟(包括操作系统);
-
Ollama 服务器在内存中加载并运行大语言模型 (LLM);
-
Open WebUI 作为连接到 Ollama 服务器的 Web 应用程序部署;
-
用户通过 Open WebUI Web 界面与 LLM 交互,发送请求并接收响应;
-
针对多卡系统的分布式计算配置;
-
监控系统状态,包括 GPU 温度和性能;
-
优化多个图形加速器的并行工作;
-
所有计算和数据处理均在服务器本地进行。管理员可以通过 OpenWebUI 工具为特定任务配置 LLM。
系统要求和技术规格¶
-
图形加速器 支持 CUDA(以下为可选配置之一,性能可能更优):
- 1x NVIDIA H100
- 2x NVIDIA A100(每张 48 GB 显存)
- 2x NVIDIA RTX 5090(每张 32 GB 显存)
- 2x NVIDIA A6000(每张 48 GB 显存)
- 3x NVIDIA RTX 4090(每张 24 GB 显存)
- 3x NVIDIA A5000(每张 24 GB 显存)
-
磁盘空间:足够大小的 SSD 用于系统和模型;
-
软件:NVIDIA 驱动程序和 CUDA;
-
显存使用:在 2K token 上下文下为 53 GB;
-
系统监控:全面检查驱动程序状态、容器和 GPU 温度。
部署 Llama-3.3-70B 后的入门指南¶
付款后,将向注册邮箱发送电子邮件,通知您服务器已准备好工作。邮件中将包含 VPS IP 地址以及连接服务器的登录名和密码信息,还有访问 OpenWebUI 的链接。我们的客户通过 服务器管理面板和 API — Invapi 管理设备。
-
访问服务器操作系统的身份验证数据(例如,通过 SSH)将通过收到的电子邮件发送给您。
-
访问带有 Open WebUI Web 界面的 Ollama 控制面板的链接:位于 Invapi 管理控制台的 Configuration >> Tags 选项卡下的 webpanel 标签中。确切的链接格式为
https://llama<Server_ID_from_Invapi>.hostkey.in,将在服务器交付时通过电子邮件发送。
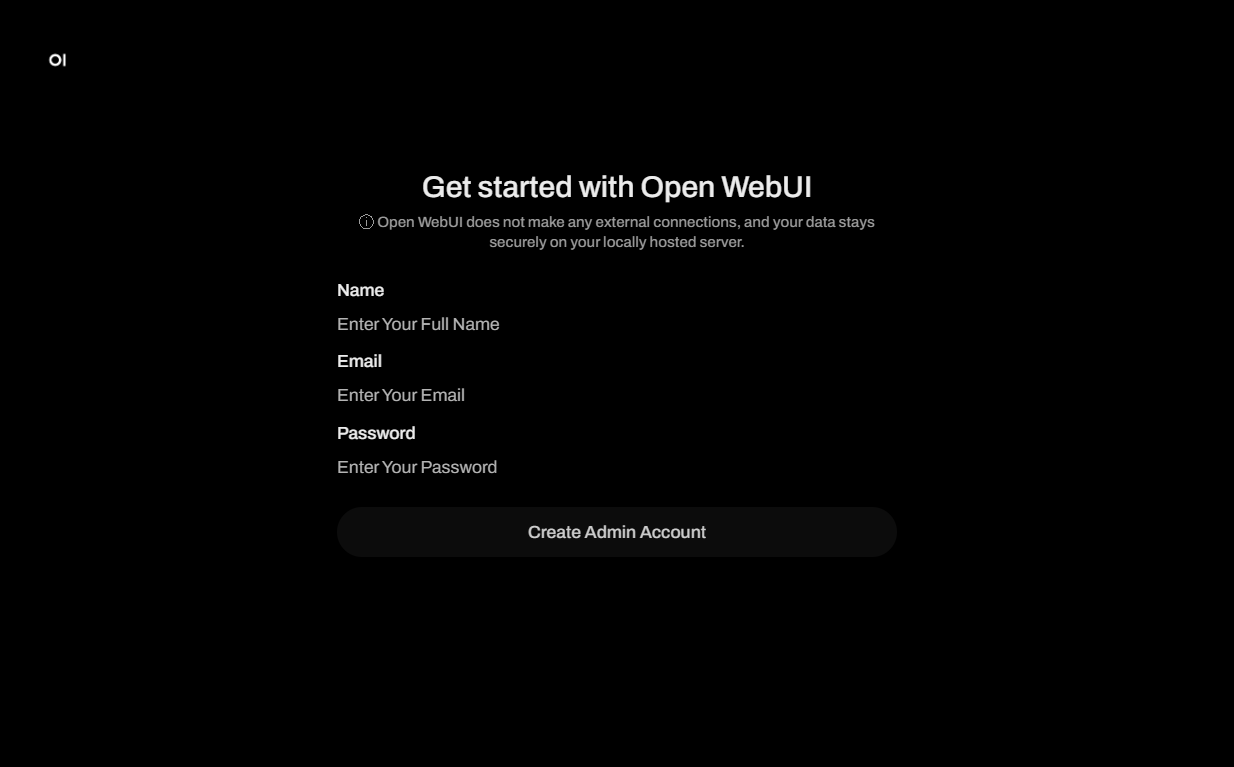
点击 webpanel 标签中的链接后,将打开 Get started with Open WebUI 登录窗口,您需要在此处为您的聊天机器人创建管理员账户名称、电子邮件和密码,然后按下 Create Admin Account 按钮:
警告
注册第一个用户后,系统会自动为其分配管理员角色。为了确保安全并控制注册流程,所有后续的注册请求都必须从 OpenWebUI 的管理员账户批准。
备注
有关使用带有 Open WebUI 的 Ollama 控制面板的详细信息,请参阅文章 AI Chatbot on Your Own Server。
备注
为了获得最佳性能,建议使用显存超过最低要求 16 GB 的 GPU。这确保了处理更大上下文和并行请求的缓冲空间。有关 Ollama 主要设置和 Open WebUI 的详细信息,请参阅 Ollama 开发者文档 和 Open WebUI 开发者文档。
使用 API 订购带有 Llama-3.3-70B 的服务器¶
要使用 API 安装此软件,请遵循 这些说明。