gpt-oss-120b¶
In dit artikel
Informatie
gpt-oss-120b is een grootschalig model met open gewichten van OpenAI, ontworpen voor taken met hoge prestaties die diep redeneren, meerstapsplanning en complexe interactie met tools vereisen. Het model bevat 120 miljard parameters, waarvan er ongeveer 21 miljard per doorgang worden geactiveerd, wat een balans biedt tussen rekenkracht en efficiëntie. Dankzij geavanceerde kwantisatiemethoden en optimalisatie kan gpt-oss-120b worden geïmplementeerd op serverhardware met 70 GB of meer videogeheugen en ondersteunt het schaalbare lokale of hybride implementatie.
Hoofdfuncties van gpt-oss-120b¶
- Schaalbare architectuur met conditionele activatie: Het model bevat 120 miljard parameters, maar activeert door het mechanisme van spaarse activatie (sparse activation) slechts ongeveer 21 miljard parameters per verzoek. Dit verlaagt de vereisten voor geheugen en rekenresources aanzienlijk zonder afbreuk te doen aan de kwaliteit.
- Geavanceerde agent-mogelijkheden: gpt-oss-120b ondersteunt een uitgebreide set tools, waaronder code-uitvoering, realtime webzoekopdrachten, API-aanroepen en het genereren van strikt gestructureerde outputs (JSON, XML, etc.). Dit maakt het tot een ideale basis voor autonome agents en complexe geautomatiseerde systemen.
- Adaptief redeneren: Het model implementeert een flexibel systeem van redeneringsniveaus – van snelle directe antwoorden tot meerstaps ketens van gedachten (chain-of-thought) en beslissingsbomen. Gebruikers kunnen de "diepte van het denken" regelen afhankelijk van de complexiteit van de taak.
- Hoge prestaties op benchmarks: gpt-oss-120b toont resultaten die vergelijkbaar zijn met propriëtaire modellen op o3- en o4-niveau, met name bij taken die logica, wiskunde, programmeren en interdisciplinaire synthese van kennis vereisen.
- Uitgebreide meertalige ondersteuning: Het model is getraind op gegevens uit meer dan 50 talen en kan effectief werken in meertalige en multiculturele contexten. Voor de beste resultaten wordt aanbevolen om de taal en culturele kaders expliciet op te geven in de prompt.
- Efficiënte kwantisatie en compatibiliteit: Ondersteuning voor MXFP4- en INT4-formaten stelt in staat het geheugengebruik aanzienlijk te verminderen en de uitvoer te versnellen zonder aanzienlijk kwaliteitsverlies. Het model is compatibel met populaire frameworks zoals vLLM, GGUF en Hugging Face Transformers.
Implementatiefuncties¶
| ID | Softwarenaam | Compatibel OS | VM | BM | VGPU | GPU | Min CPU (Kernen) | Min RAM (GB) | Min HDD/SSD (GB) | Aangepast Domein | Actief |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 415 | gpt-oss:120b | Ubuntu 22.04 | - | - | + | + | 16 | 128 | 240 | Nee | BESTELLEN |
Technische specificaties van de build:
- Ubuntu 22.04 met kernel bijgewerkt naar versie 6;
- Nieuwste Nvidia-drivers;
- CUDA Toolkit;
- Ollama voor het beheren van modellen;
- OpenWebUI voor webinterface.
Installatiefuncties:
- De installatietijd is 35-45 minuten, inclusief het instellen van het besturingssysteem;
- De Ollama-server laadt en voert het gpt-oss-120b-model uit in GPU/RAM-geheugen;
- Open WebUI wordt geïmplementeerd als een webapplicatie die is verbonden met de Ollama-server;
- Gebruikers interacteren met het model via de Open WebUI-webinterface voor programmeer- en agent-taken;
- Alle berekeningen en codeverwerking vinden lokaal op de server plaats;
- Beheerders kunnen het model configureren voor specifieke ontwikkelingstaken met behulp van OpenWebUI-tools;
- Ondersteuning voor verschillende kwantisatieniveaus om het geheugengebruik te optimaliseren.
Aan de slag na het implementeren van gpt-oss-120b¶
Na betaling wordt er een melding over de serverklaarheid verzonden naar het e-mailadres dat tijdens de bestelling is geregistreerd. Hierin staan het VPS-IP-adres, de inloggegevens en het wachtwoord voor servertoegang, evenals een link naar het OpenWebUI-configuratiepaneel. Klanten beheren apparatuur via het Server Management Panel en API — Invapi.
- Inloggegevens voor toegang tot het OS-server (bijv. via SSH) worden verzonden in de ontvangen e-mail.
- Link naar Ollama-configuratiepaneel met Open WebUI-webinterface: in de webpanel tag in het tabblad Configuration* >> **Tags van het Invapi-configuratiepaneel. De exacte link, bijv.
https://gpt-oss<Server_ID_from_Invapi>.hostkey.in, wordt verstrekt in de e-mail die bij de levering van de server wordt verzonden.
Bij het eerste bezoek aan de link van de webpanel tag opent er een welkomstpagina. Klik op de knop Get started om met de installatie te beginnen.
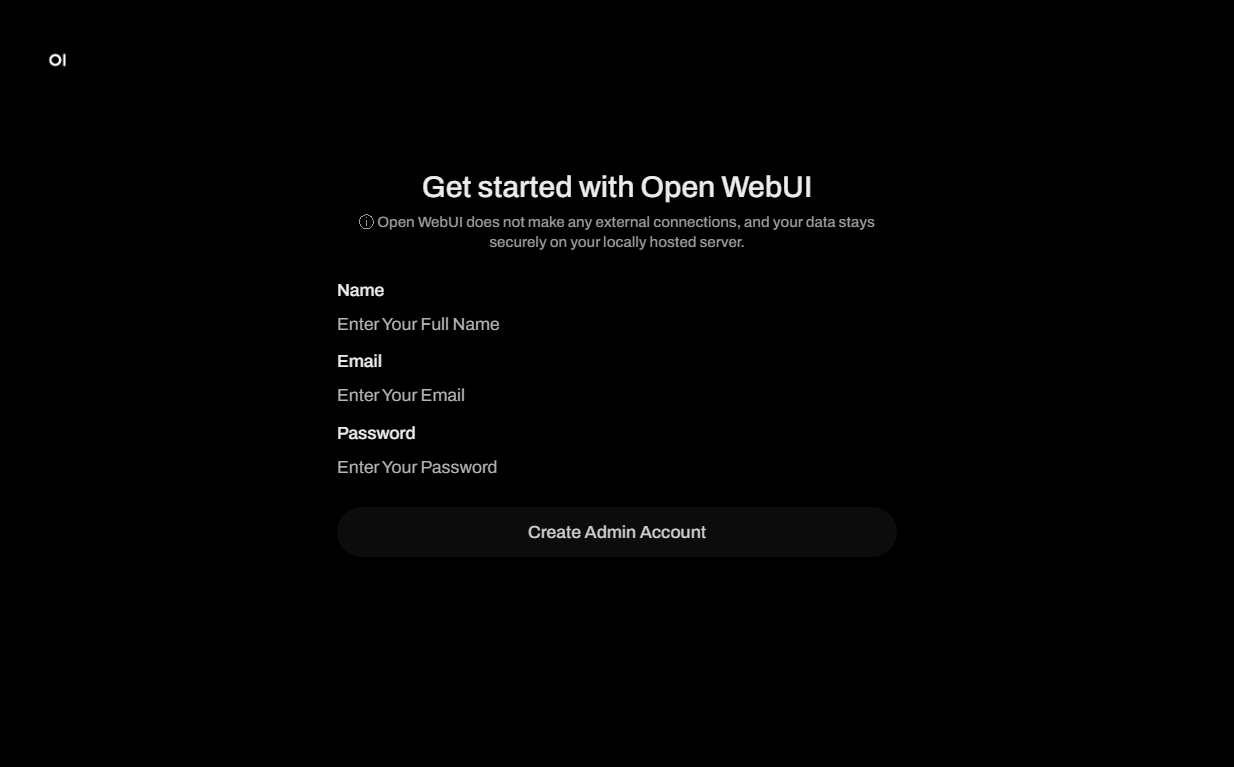
Na het klikken op de link van de tag webpanel opent er een inlogvenster Get started with Open WebUI, waarin u een admin-accountnaam, e-mailadres en wachtwoord voor uw chatbot moet maken en vervolgens op de knop Create Admin Account drukt:
Let op
Na het registreren van de eerste gebruiker wijst het systeem deze automatisch een beheerdersrol toe. Om de veiligheid en controle over het registratieproces te waarborgen, moeten alle volgende registratieverzoeken worden goedgekeurd in OpenWebUI vanuit het beheerdersaccount.
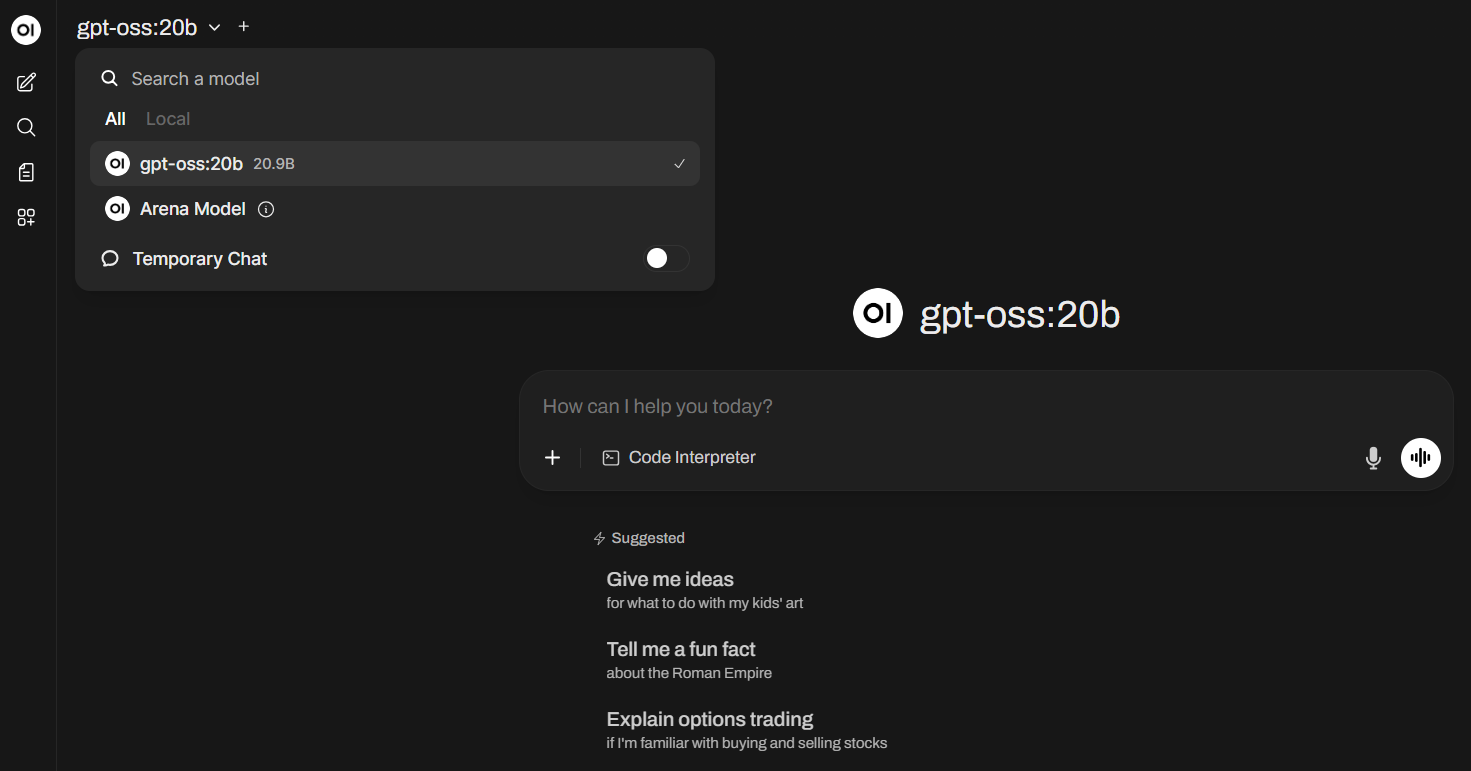
Na succesvolle registratie opent het hoofdinterface van Open WebUI met toegang tot Gpt-oss-20b:
Opmerking
Gedetailleerde informatie over het gebruik van het Ollama-configuratiepaneel met Open WebUI is te vinden in het artikel AI Chatbot op uw eigen server.
Opmerking
Voor optimale werking met het gpt-oss-120b-model wordt aanbevolen om een GPU met minimaal 70 GB videogeheugen te gebruiken voor het 120B-model. Voor efficiënte verwerking van lange codecontexten en complexe agent-taken raden we aan GPUs met 80 GB videogeheugen te gebruiken. Gedetailleerde informatie over de belangrijkste Ollama-instellingen en Open WebUI is te vinden in de Ollama-ontwikkelaarsdocumentatie en in de Open WebUI-ontwikkelaarsdocumentatie.
Aanbevelingen voor gebruik
Om de efficiëntie van het gpt-oss 20B-model te maximaliseren, wordt aanbevolen om:
- Het model te gebruiken voor redeneertaken, inclusief chain-of-thought-verwerking. Het model ondersteunt instelbare niveaus van redeneren: laag, medium en hoog, die worden geconfigureerd via een system prompt.
- De ingebouwde agent-mogelijkheden van het model te gebruiken, zoals function calling, Python-code-uitvoering en gestructureerde outputs.
- Het model in te zetten voor meerstaps ontwikkelingstaken waarbij gebruik wordt gemaakt van de agent-mogelijkheden.
- Het model te integreren met bestaande ontwikkelingstools via API, met inachtneming van het feit dat het tuning ondersteunt en werkt in het OpenAI Harmony-responsformaat. Het model is ontworpen voor efficiënte implementatie met lage latentie, ook lokaal.