Apache Spark¶
In this article
Information
Apache Spark is a powerful and fast engine for big data processing that can be used for various tasks, such as real-time data stream processing, machine learning, and database analysis. Spark provides a flexible API in multiple programming languages, including Scala, Java, Python, and R.
Key Features of Apache Spark¶
- High Performance: Spark uses distributed data processing and optimized algorithms, allowing it to process large volumes of data faster than traditional solutions.
- Distributeness: Spark can operate on clusters of multiple nodes, enabling you to scale data processing as needed.
- Diverse APIs: Spark offers APIs in various programming languages, making it suitable for different scenarios and development teams.
- Support for Various Data Types: Spark can handle different data types, including structured data (tables), unstructured data (text, images), and semi-structured data (JSON).
- Spark GraphX: A graphical API that enables operations on large graphs.
Deployment Features¶
| ID | Name of Software | Compatible OS | VM | BM | VGPU | GPU | Min CPU (Cores) | Min RAM (GB) | Min HDD/SDD (GB) | Custom Domain | Active |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 204 | Apache Spark | Ubuntu 22.04 | + | + | + | + | 6 | 8 | 160 | No | ORDER |
- Access to the control panel:
https://spark{Server_ID_from_Invapi}.hostkey.in - The time it takes to install the control panel along with the OS is about 15 minutes.
Note
Unless otherwise specified, by default we install the latest release version of software from the developer's website or operating system repositories.
Getting Started After Deploying Apache Spark¶
After paying for your order, you will receive a notification via email (to the address registered during signup) when the server is ready to use. This notification will include the VPS IP address and login credentials for connection. Our company's clients manage their equipment through the server control panel and API - Invapi.
You can find authentication data, which can be found in the Configuration* >> **Tags tab of the server control panel or in the email sent to you after the server is ready for use:
- Link to access the Apache Airflow web interface: in the tag webpanel;
- Login and Password: provided in the email sent to your registered email address when the server is ready for use.
Configuring Apache Spark¶
Spark can be launched on a local computer or in a distributed environment. Before clicking on the link from the tag webpanel you need to:
Connect to the server via SSH:
Then launch the required application using the command from the table in the Launching Components section.
Otherwise, clicking on the link will display a 502 (Bad Gateway) error.
Launching Components¶
You can start various Spark components such as Application, Standalone Master, Standalone Worker, and History Server with a web interface using commands from the table below.
| Name | Local Address and Port | External Address | Launch Command |
|---|---|---|---|
| Application | localhost:4040 | https://spark{Server_ID_from_Invapi}.hostkey.in | /root/spark-3.5.3-bin-hadoop3/bin/./spark-shell |
| Standalone Master | localhost:8080 | https://spark{Server_ID_from_Invapi}.hostkey.in/master | /root/spark-3.5.3-bin-hadoop3/sbin/./start-master.sh |
| Standalone Worker | localhost:8081 | https://spark{Server_ID_from_Invapi}.hostkey.in/worker | /root/spark-3.5.3-bin-hadoop3/sbin/./start-master.sh spark://hostname:port |
| History Server | localhost:18080 | https://spark{Server_ID_from_Invapi}.hostkey.in/history | mkdir /tmp/spark-events/root/spark-3.5.3-bin-hadoop3/sbin/./start-history-server.sh |
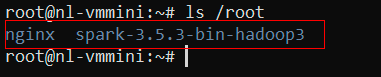
Please note that the commands for launching Spark components may vary depending on the version used. The examples above use Spark version 3.5.3. When updating Spark, you will need to adjust the paths in the commands accordingly. It's always recommended to consult the latest Spark documentation for the most accurate information about component launch commands. To check the version, connect to the server via SSH and enter the command:
The output of this command will list the contents of the /root directory, including the spark directory with the installed version:
After launching the Spark components, you can access their web interfaces through the specified external addresses. Consider an example of the Spark Application interface:
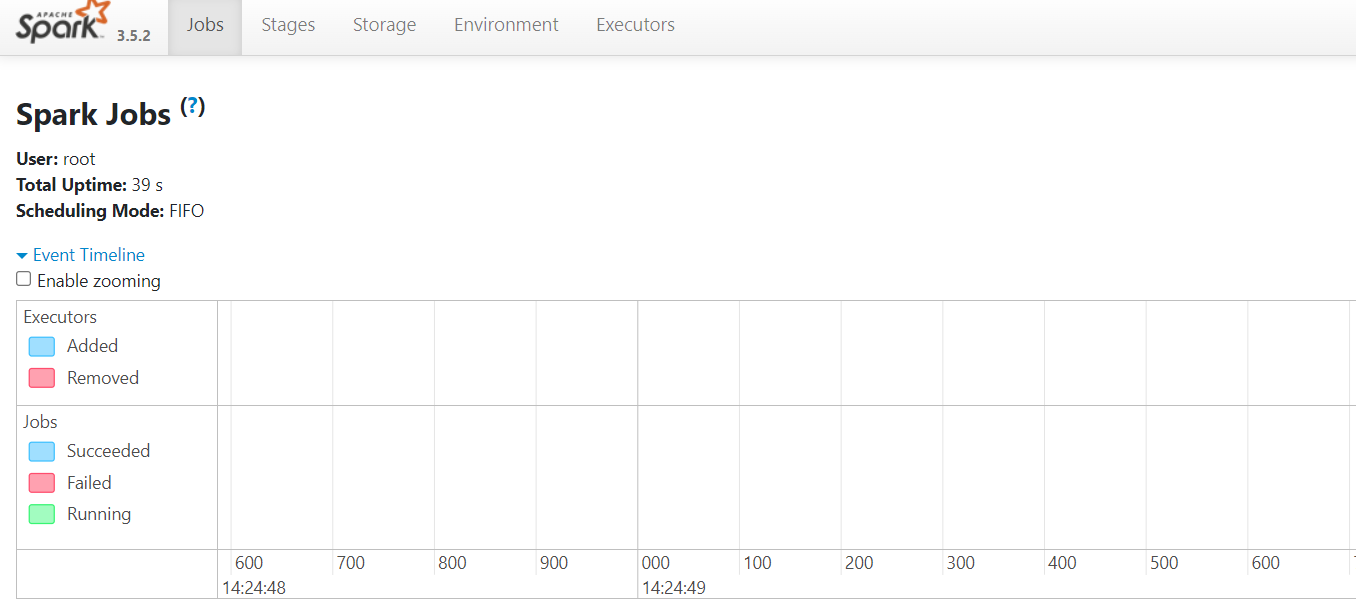
This example demonstrates the Spark Application interface accessible at https://spark{Server_ID_from_Invapi}.hostkey.in. This interface displays information about running tasks, processing stages, memory usage, and other key metrics.
It is important to note that links to other Spark components (e.g., Standalone Master or Worker) in this interface will not function when connecting from another machine. This is due to security settings: the components are configured for local operation, and only the web interface accessible via the domain name is exposed externally.
To modify this configuration and enable external access to all components, you need to perform the following steps:
- Stop and remove the current Docker container by executing the command
docker compose up downin the/root/nginxdirectory. - Delete the line
SPARK_LOCAL_IP="127.0.0.1"from the/etc/environmentfile.
After these changes, the Spark web interface will be accessible via the white IP address without an SSL certificate. This modification can also resolve connectivity issues between components if they arise during operation.
Note
It's important to remember that this configuration reduces the security level of the Spark cluster. It should only be used when necessary and in a secure network environment. If you use this configuration, consider configuring SSL connections within Spark itself or implementing other security measures to protect the cluster.
Customizing Paths¶
- Stop the Docker container by executing the command
docker compose up downin the/root/nginxdirectory. - Make the necessary edits to the Nginx configuration file:
/data/nginx/user_conf.d/spark{Server_ID_from_Invapi}.hostkey.in.conf. - Restart the Docker container from the
/root/nginxdirectory using the commanddocker compose up -d.
Note
Detailed information about basic Apache Spark settings can be found in the developer documentation.
Ordering a Server with Apache Spark using API¶
To install this software using the API, follow these instructions