Apache Spark¶
Dans cet article
Information
Apache Spark est un moteur puissant et rapide pour le traitement des mégadonnées (big data) qui peut être utilisé pour diverses tâches, telles que le traitement de flux de données en temps réel, l'apprentissage automatique (machine learning) et l'analyse de bases de données. Spark fournit une API flexible dans plusieurs langages de programmation, notamment Scala, Java, Python et R.
Fonctionnalités clés d'Apache Spark¶
- Hautes performances : Spark utilise le traitement distribué des données et des algorithmes optimisés, ce qui lui permet de traiter de grands volumes de données plus rapidement que les solutions traditionnelles.
- Distribution : Spark peut fonctionner sur des clusters de plusieurs nœuds, vous permettant de mettre à l'échelle le traitement des données selon vos besoins.
- API diverses : Spark propose des API dans divers langages de programmation, ce qui le rend adapté à différents scénarios et équipes de développement.
- Prise en charge de divers types de données : Spark peut gérer différents types de données, y compris les données structurées (tables), les données non structurées (texte, images) et les données semi-structurées (JSON).
- Spark GraphX : Une API graphique qui permet d'effectuer des opérations sur de grands graphes.
Fonctionnalités de déploiement¶
| ID | Nom du logiciel | Système d'exploitation compatible | VM | BM | VGPU | GPU | Min CPU (Cœurs) | Min RAM (GB) | Min HDD/SSD (GB) | Domaine personnalisé | Actif |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 204 | Apache Spark | Ubuntu 22.04 | + | + | + | + | 6 | 8 | 160 | Non | COMMANDER |
- Accès au panneau de contrôle :
https://spark{Server_ID_from_Invapi}.hostkey.in - Le temps nécessaire pour installer le panneau de contrôle ainsi que le système d'exploitation est d'environ 15 minutes.
Remarque
Sauf indication contraire, nous installons par défaut la dernière version de sortie du logiciel depuis le site Web du développeur ou les dépôts du système d'exploitation.
Premiers pas après le déploiement d'Apache Spark¶
Après avoir payé votre commande, vous recevrez une notification par e-mail (à l'adresse enregistrée lors de l'inscription) lorsque le serveur sera prêt à être utilisé. Cette notification inclura l'adresse IP du VPS et les informations d'identification pour la connexion. Les clients de notre entreprise gèrent leur équipement via le panneau de contrôle du serveur et l'API - Invapi.
Vous pouvez trouver les données d'authentification, accessibles dans l'onglet Configuration >> Tags du panneau de contrôle du serveur ou dans l'e-mail envoyé après que le serveur est prêt à être utilisé :
- Lien d'accès à l'interface web d'Apache Spark : dans la balise webpanel ;
- Login et Password : fournis dans l'e-mail envoyé à votre adresse e-mail enregistrée lorsque le serveur est prêt à être utilisé.
Configuration d'Apache Spark¶
Spark peut être lancé sur un ordinateur local ou dans un environnement distribué. Avant de cliquer sur le lien de la balise webpanel, vous devez :
Se connecter au serveur via SSH :
Puis lancez l'application requise en utilisant la commande du tableau dans la section Lancement des composants.
Sinon, cliquer sur le lien affichera une erreur 502 (Bad Gateway).
Lancement des composants¶
Vous pouvez démarrer divers composants Spark tels que l'Application, le Standalone Master, le Standalone Worker et le History Server avec une interface web en utilisant les commandes du tableau ci-dessous.
| Nom | Adresse et port locaux | Adresse externe | Commande de lancement |
|---|---|---|---|
| Application | localhost:4040 | https://spark{Server_ID_from_Invapi}.hostkey.in | /root/spark-3.5.3-bin-hadoop3/bin/./spark-shell |
| Standalone Master | localhost:8080 | https://spark{Server_ID_from_Invapi}.hostkey.in/master | /root/spark-3.5.3-bin-hadoop3/sbin/./start-master.sh |
| Standalone Worker | localhost:8081 | https://spark{Server_ID_from_Invapi}.hostkey.in/worker | /root/spark-3.5.3-bin-hadoop3/sbin/./start-master.sh spark://hostname:port |
| History Server | localhost:18080 | https://spark{Server_ID_from_Invapi}.hostkey.in/history | mkdir /tmp/spark-events/root/spark-3.5.3-bin-hadoop3/sbin/./start-history-server.sh |
Veuillez noter que les commandes pour lancer les composants Spark peuvent varier selon la version utilisée. Les exemples ci-dessus utilisent la version 3.5.3 de Spark. Lors de la mise à jour de Spark, vous devrez ajuster les chemins dans les commandes en conséquence. Il est toujours recommandé de consulter la dernière documentation Spark pour obtenir les informations les plus précises sur les commandes de lancement des composants. Pour vérifier la version, connectez-vous au serveur via SSH et entrez la commande :
La sortie de cette commande listera le contenu du répertoire /root, y compris le répertoire spark avec la version installée :
Après avoir lancé les composants Spark, vous pouvez accéder à leurs interfaces web via les adresses externes spécifiées. Prenons l'exemple de l'interface Spark Application :
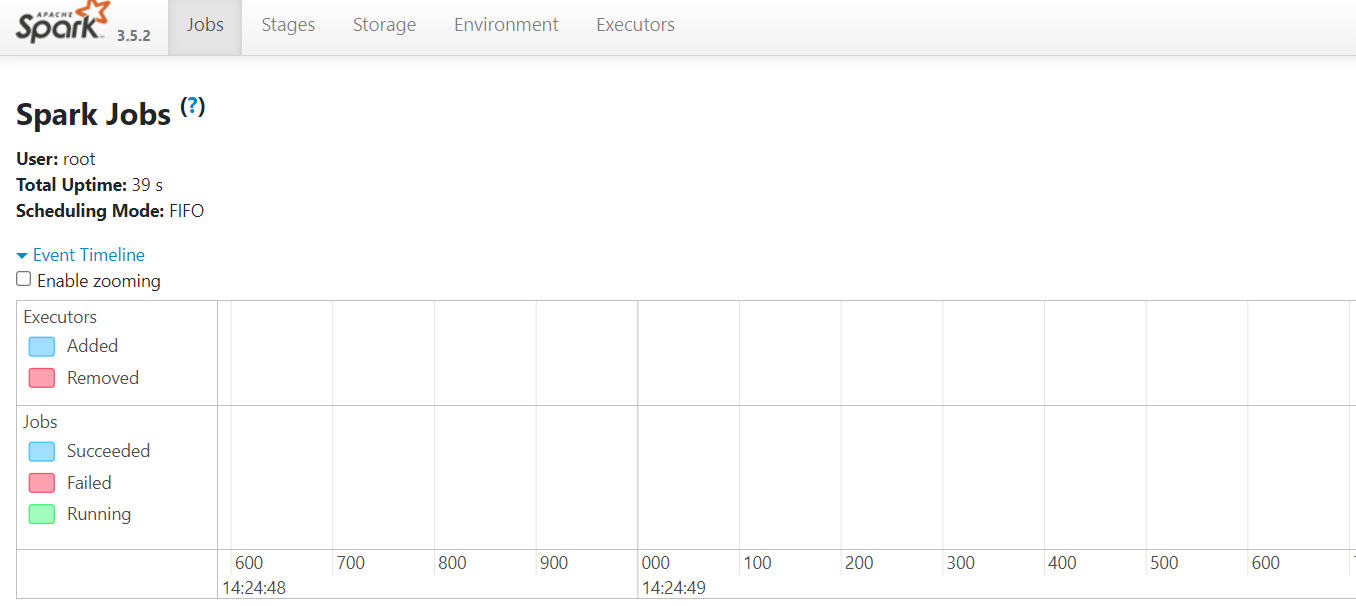
Cet exemple illustre l'interface Spark Application accessible à l'adresse https://spark{Server_ID_from_Invapi}.hostkey.in. Cette interface affiche des informations sur les tâches en cours, les étapes de traitement, l'utilisation de la mémoire et d'autres métriques clés.
Il est important de noter que les liens vers d'autres composants Spark (par exemple, Standalone Master ou Worker) dans cette interface ne fonctionneront pas lors de la connexion depuis une autre machine. Cela est dû aux paramètres de sécurité : les composants sont configurés pour un fonctionnement local, et seule l'interface web accessible via le nom de domaine est exposée de manière externe.
Pour modifier cette configuration et permettre l'accès externe à tous les composants, vous devez effectuer les étapes suivantes :
- Arrêtez et supprimez le conteneur Docker actuel en exécutant la commande
docker compose up downdans le répertoire/root/nginx. - Supprimez la ligne
SPARK_LOCAL_IP="127.0.0.1"du fichier/etc/environment.
Après ces modifications, l'interface web Spark sera accessible via l'adresse IP blanche sans certificat SSL. Cette modification peut également résoudre les problèmes de connectivité entre les composants s'ils surviennent pendant le fonctionnement.
Remarque
Il est important de se rappeler que cette configuration réduit le niveau de sécurité du cluster Spark. Elle ne doit être utilisée que si nécessaire et dans un environnement réseau sécurisé. Si vous utilisez cette configuration, envisagez de configurer les connexions SSL au sein de Spark lui-même ou d'implémenter d'autres mesures de sécurité pour protéger le cluster.
Personnalisation des chemins¶
- Arrêtez le conteneur Docker en exécutant la commande
docker compose up downdans le répertoire/root/nginx. - Apportez les modifications nécessaires au fichier de configuration Nginx :
/data/nginx/user_conf.d/spark{Server_ID_from_Invapi}.hostkey.in.conf. - Redémarrez le conteneur Docker depuis le répertoire
/root/nginxen utilisant la commandedocker compose up -d.
Remarque
Des informations détaillées sur les paramètres de base d'Apache Spark peuvent être trouvées dans la documentation du développeur.
Commande d'un serveur avec Apache Spark via l'API¶
Pour installer ce logiciel via l'API, suivez ces instructions.