Llama-3.3-70B¶
Dans cet article
Information
Llama-3.3-70B est un modèle de langage haute performance avec 70 milliards de paramètres pour le déploiement local via Ollama. Le modèle nécessite des ressources de calcul puissantes avec au moins 53 Go de mémoire vidéo (NVIDIA A100/H100 ou plusieurs GPU grand public). Le déploiement sur Ubuntu 22.04 prend en charge le calcul distribué et l'intégration avec Open Web UI, offrant un contrôle total des données et une optimisation des performances.
Fonctionnalités principales de Llama-3.3-70B¶
-
Architecture haute performance : le modèle dispose de 70 milliards de paramètres et est optimisé pour le traitement de tâches complexes avec une précision inégalée grâce aux technologies modernes de calcul distribué ;
-
Intégration avec Open Web UI : une interface web moderne disponible sur le port 8080, garantissant un contrôle total sur les données, les ressources de calcul et les processus de traitement ;
-
Calcul distribué : prise en charge avancée des configurations multi-cartes avec équilibrage de charge automatique entre plusieurs GPU ;
-
Évolutivité : possibilité de mise à l'échelle horizontale en ajoutant des GPU supplémentaires pour augmenter les performances ;
-
Performance : utilisation de la technologie LLAMA_FLASH_ATTENTION pour optimiser les calculs et accélérer le traitement des requêtes ;
-
Tolérance aux pannes : un système de récupération automatique assure un fonctionnement continu.
-
Exemples d'utilisation :
-
Support client : automatisation des réponses aux requêtes des utilisateurs ;
-
Éducation : création de matériel pédagogique, assistance à la résolution de problèmes ;
-
Marketing : génération de textes publicitaires, analyse des avis ;
-
Développement logiciel : création et documentation de code.
-
Fonctionnalités de déploiement¶
| ID | Nom du logiciel | Système d'exploitation compatible | VM | BM | VGPU | GPU | Min CPU (Cœurs) | Min RAM (GB) | Min HDD/SSD (GB) | Domaine personnalisé | Actif |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 253 | Llama-3.3-70B | Ubuntu 22.04 | - | - | + | + | 4 | 64 | - | Non | COMMANDER |
-
Le temps d'installation est de 15 à 30 minutes, système d'exploitation inclus ;
-
Le serveur Ollama charge et exécute le LLM en mémoire ;
-
Open WebUI est déployé en tant qu'application web connectée au serveur Ollama ;
-
Les utilisateurs interagissent avec le LLM via l'interface web Open WebUI, en envoyant des requêtes et en recevant des réponses ;
-
Configuration pour le calcul distribué sur les systèmes multi-cartes ;
-
Surveillance de l'état du système, y compris la température et les performances du GPU ;
-
Optimisation du travail parallèle de plusieurs accélérateurs graphiques ;
-
Tous les calculs et le traitement des données se produisent localement sur le serveur. Les administrateurs peuvent configurer le LLM pour des tâches spécifiques via les outils OpenWebUI.
Configuration système et spécifications techniques¶
-
Accélérateur graphique avec prise en charge CUDA (l'une des options, peut être meilleure) :
- 1x NVIDIA H100
- 2x NVIDIA A100 (48 Go de mémoire vidéo chacun)
- 2x NVIDIA RTX 5090 (32 Go de mémoire vidéo chacun)
- 2x NVIDIA A6000 (48 Go de mémoire vidéo chacun)
- 3x NVIDIA RTX 4090 (24 Go de mémoire vidéo chacun)
- 3x NVIDIA A5000 (24 Go de mémoire vidéo chacun)
-
Espace disque : SSD de taille suffisante pour le système et le modèle ;
-
Logiciel : pilotes NVIDIA et CUDA ;
-
Utilisation de la mémoire vidéo : 53 Go avec un contexte de 2K tokens ;
-
Surveillance du système : vérification complète de l'état des pilotes, des conteneurs et de la température du GPU.
Prise en main après le déploiement de Llama-3.3-70B¶
Après le paiement, un e-mail sera envoyé à l'adresse e-mail enregistrée vous informant que le serveur est prêt à fonctionner. Il inclura l'adresse IP du VPS ainsi que les informations d'identification (nom d'utilisateur et mot de passe) pour se connecter au serveur et un lien pour accéder à OpenWebUI. Les clients de notre entreprise gèrent l'équipement via le panneau de gestion des serveurs et l'API — Invapi.
-
Données d'authentification pour accéder au système d'exploitation du serveur (par exemple, via SSH) vous seront envoyées dans l'e-mail reçu.
-
Lien d'accès au panneau de contrôle Ollama avec l'interface web Open WebUI : sous la balise webpanel dans l'onglet Configuration* >> **Tags de la console de gestion Invapi. Le lien exact sous la forme
https://llama<Server_ID_from_Invapi>.hostkey.inest envoyé par e-mail lors de la remise du serveur.
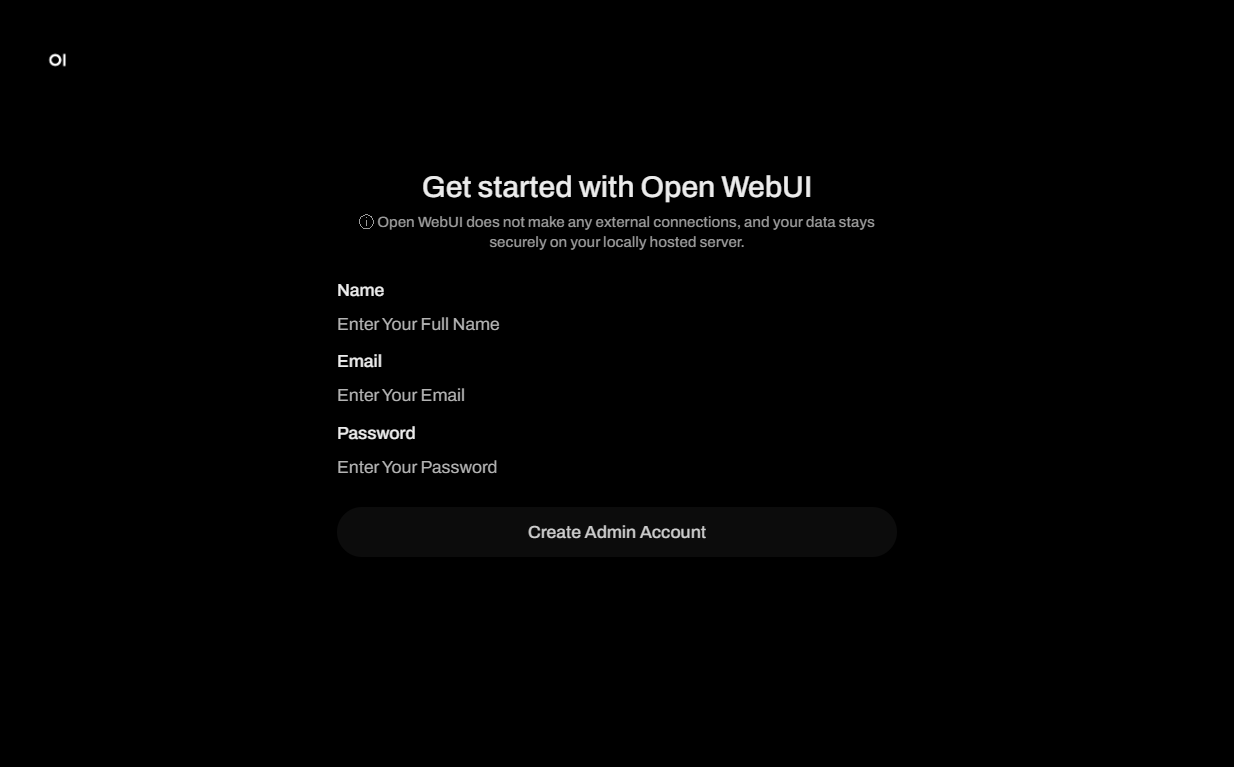
Après avoir cliqué sur le lien de la balise webpanel, une fenêtre de connexion Get started with Open WebUI s'ouvrira, où vous devrez créer un nom de compte administrateur, un e-mail et un mot de passe pour votre chatbot, puis appuyer sur le bouton Create Admin Account :
Attention
Après l'enregistrement du premier utilisateur, le système lui attribue automatiquement un rôle d'administrateur. Pour garantir la sécurité et le contrôle du processus d'inscription, toutes les demandes d'inscription ultérieures doivent être approuvées dans OpenWebUI depuis le compte administrateur.
Remarque
Des informations détaillées sur l'utilisation du panneau de contrôle Ollama avec Open WebUI peuvent être trouvées dans l'article Chatbot IA sur votre propre serveur.
Remarque
Pour des performances optimales, il est recommandé d'utiliser des GPU avec plus de 16 Go de mémoire vidéo, le minimum requis. Cela garantit une marge pour le traitement de contextes plus importants et de requêtes parallèles. Des informations détaillées sur les paramètres principaux d'Ollama et d'Open WebUI peuvent être trouvées dans la documentation des développeurs d'Ollama et dans la documentation des développeurs d'Open WebUI.
Commande d'un serveur avec Llama-3.3-70B via l'API¶
Pour installer ce logiciel via l'API, suivez ces instructions.