gpt-oss-120b¶
Dans cet article
Information
gpt-oss-120b est un modèle de grande échelle aux poids ouverts d'OpenAI, conçu pour des tâches haute performance nécessitant un raisonnement approfondi, une planification en plusieurs étapes et une interaction complexe avec des outils. Le modèle contient 120 milliards de paramètres, dont environ 21 milliards sont activés par passage, offrant un équilibre entre puissance de calcul et efficacité. Grâce à des méthodes de quantification avancées et à l'optimisation, gpt-oss-120b peut être déployé sur du matériel serveur disposant de 70 Go ou plus de mémoire vidéo et prend en charge un déploiement local ou hybride évolutif.
Fonctionnalités principales de gpt-oss-120b¶
- Architecture évolutive avec activation conditionnelle : Le modèle contient 120 milliards de paramètres, mais grâce au mécanisme d'activation creuse (sparse activation), il n'active qu'environ 21 milliards de paramètres par requête. Cela réduit considérablement les exigences en matière de mémoire et de ressources de calcul sans compromettre la qualité.
- Capacités d'agent avancées : gpt-oss-120b prend en charge un ensemble étendu d'outils, y compris l'exécution de code, la recherche Web en temps réel, l'appel d'API et la génération de sorties strictement structurées (JSON, XML, etc.). Cela en fait une base idéale pour les agents autonomes et les systèmes automatisés complexes.
- Raisonnement adaptatif : Le modèle implémente un système flexible de niveaux de raisonnement — des réponses directes rapides aux chaînes de pensée en plusieurs étapes (chain-of-thought) et aux arbres de décision. Les utilisateurs peuvent contrôler la « profondeur de réflexion » en fonction de la complexité de la tâche.
- Hautes performances sur les benchmarks : gpt-oss-120b démontre des résultats comparables aux modèles propriétaires des niveaux o3 et o4, en particulier dans les tâches nécessitant de la logique, des mathématiques, de la programmation et une synthèse interdisciplinaire des connaissances.
- Support multilingue étendu : Le modèle est entraîné sur des données de plus de 50 langues et peut fonctionner efficacement dans des contextes multilingues et multiculturels. Pour de meilleurs résultats, il est recommandé de spécifier explicitement la langue et les cadres culturels dans l'invite (prompt).
- Quantification efficace et compatibilité : La prise en charge des formats MXFP4 et INT4 permet de réduire considérablement l'utilisation de la mémoire et d'accélérer la sortie sans perte de qualité substantielle. Le modèle est compatible avec des frameworks populaires tels que vLLM, GGUF et Hugging Face Transformers.
Fonctionnalités de déploiement¶
| ID | Nom du logiciel | Système d'exploitation compatible | VM | BM | VGPU | GPU | Min CPU (Cœurs) | Min RAM (GB) | Min HDD/SSD (GB) | Domaine personnalisé | Actif |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 415 | gpt-oss:120b | Ubuntu 22.04 | - | - | + | + | 16 | 128 | 240 | Non | COMMANDER |
Spécifications techniques de la construction :
- Ubuntu 22.04 avec noyau mis à jour vers la version 6 ;
- Derniers pilotes Nvidia ;
- CUDA Toolkit ;
- Ollama pour la gestion des modèles ;
- OpenWebUI pour l'interface Web.
Caractéristiques d'installation :
- Le temps d'installation est de 35 à 45 minutes, incluant la configuration du système d'exploitation ;
- Le serveur Ollama charge et exécute le modèle gpt-oss-120b en mémoire GPU/RAM ;
- Open WebUI est déployé en tant qu'application Web connectée au serveur Ollama ;
- Les utilisateurs interagissent avec le modèle via l'interface Web Open WebUI pour les tâches de programmation et d'agent ;
- Tous les calculs et le traitement du code se produisent localement sur le serveur ;
- Les administrateurs peuvent configurer le modèle pour des tâches de développement spécifiques à l'aide des outils OpenWebUI ;
- Prise en charge de divers niveaux de quantification pour optimiser l'utilisation de la mémoire.
Prise en main après le déploiement de gpt-oss-120b¶
Après le paiement, une notification concernant la disponibilité du serveur sera envoyée à l'adresse e-mail enregistrée lors de la commande. Elle contiendra l'adresse IP du VPS, le nom d'utilisateur et le mot de passe pour l'accès au serveur, ainsi qu'un lien vers le panneau de contrôle OpenWebUI. Les clients gèrent l'équipement via le Panneau de gestion des serveurs et l'API — Invapi.
- Les identifiants pour l'accès au serveur du système d'exploitation (par exemple, via SSH) seront envoyés dans l'e-mail reçu.
- Lien vers le panneau de contrôle Ollama avec l'interface Web Open WebUI : dans la balise webpanel de l'onglet Configuration >> Tags du panneau de contrôle d'Invapi. Le lien exact, par exemple
https://gpt-oss<Server_ID_from_Invapi>.hostkey.in, est fourni dans l'e-mail envoyé lors de la livraison du serveur.
Lors de la première visite du lien de la balise webpanel, une page d'accueil s'ouvrira. Cliquez sur le bouton Get started pour commencer la configuration.
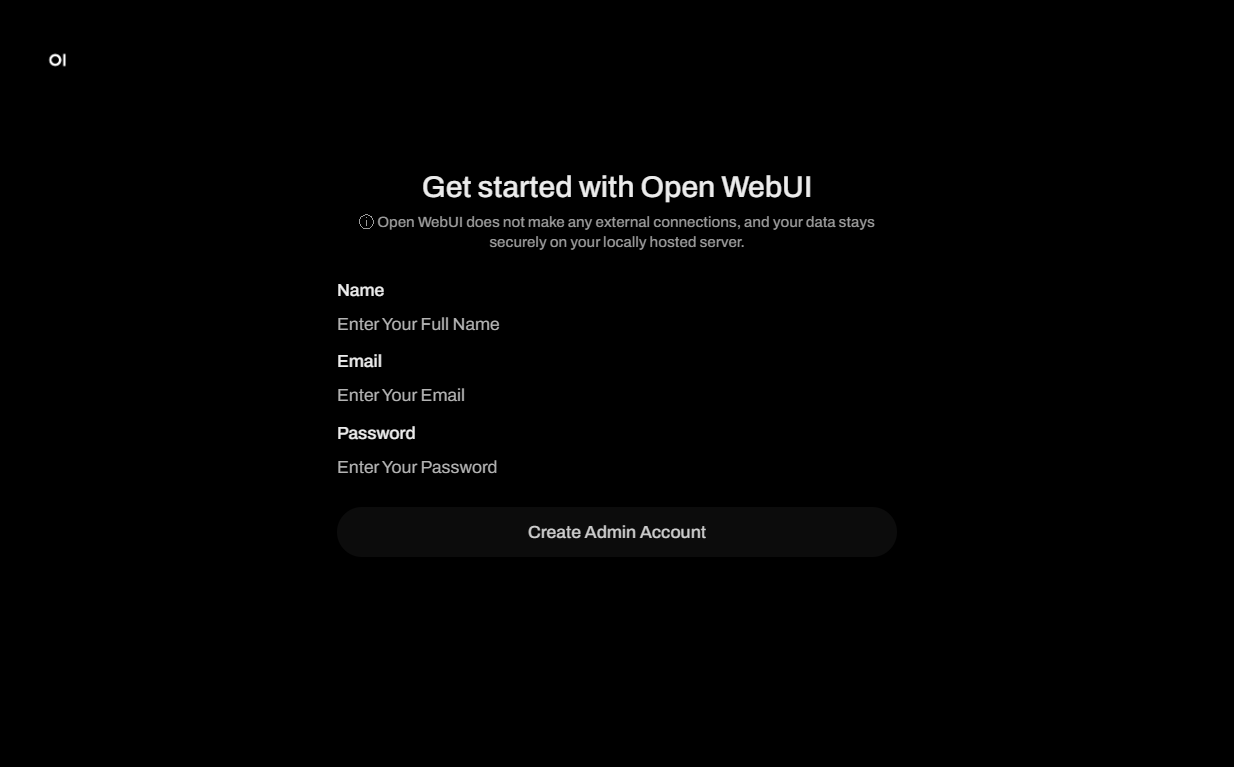
Après avoir cliqué sur le lien de la balise webpanel, une fenêtre de connexion Get started with Open WebUI s'ouvrira, où vous devrez créer un nom de compte administrateur, un e-mail et un mot de passe pour votre chatbot, puis appuyer sur le bouton Create Admin Account :
Attention
Après l'enregistrement du premier utilisateur, le système lui attribue automatiquement un rôle d'administrateur. Pour garantir la sécurité et le contrôle du processus d'enregistrement, toutes les demandes d'enregistrement ultérieures doivent être approuvées dans OpenWebUI depuis le compte administrateur.
Après un enregistrement réussi, l'interface principale Open WebUI avec accès à gpt-oss-120b s'ouvrira :
Remarque
Des informations détaillées sur l'utilisation du panneau de contrôle Ollama avec Open WebUI peuvent être trouvées dans l'article Chatbot IA sur votre propre serveur.
Remarque
Pour un fonctionnement optimal avec le modèle gpt-oss-120b, il est recommandé d'utiliser un GPU avec au moins 70 Go de mémoire vidéo pour le modèle 120B. Pour un traitement efficace de longs contextes de code et de tâches d'agent complexes, nous recommandons d'utiliser des GPU avec 80 Go de mémoire vidéo. Des informations détaillées sur les paramètres principaux d'Ollama et d'Open WebUI peuvent être trouvées dans la documentation développeur d'Ollama et dans la documentation développeur d'Open WebUI.
Recommandations d'utilisation
Pour maximiser l'efficacité du modèle gpt-oss-120b, il est recommandé de :
- Utiliser le modèle pour les tâches de raisonnement, y compris le traitement chain-of-thought. Le modèle prend en charge des niveaux de raisonnement ajustables : faible, moyen et élevé, qui sont configurés via une invite système.
- Exploiter les capacités d'agent intégrées du modèle, telles que l'appel de fonctions, l'exécution de code Python et les sorties structurées.
- Employer le modèle pour des tâches de développement en plusieurs étapes en tirant parti de ses capacités d'agent.
- Intégrer le modèle avec les outils de développement existants via l'API, en tenant compte du fait qu'il prend en charge l'ajustement (tuning) et fonctionne au format de réponse OpenAI Harmony. Le modèle est conçu pour un déploiement efficace avec une faible latence, y compris localement.
Commande d'un serveur avec gpt-oss-120b via l'API¶
Pour installer ce logiciel via l'API, suivez ces instructions.