Llama-3.3-70B¶
En este artículo
Información
Llama-3.3-70B es un modelo de lenguaje de alto rendimiento con 70 mil millones de parámetros para implementación local a través de Ollama. El modelo requiere recursos de computación potentes con al menos 53 GB de memoria de vídeo (NVIDIA A100/H100 o varias GPUs de consumo). La implementación en Ubuntu 22.04 admite computación distribuida e integración con Open Web UI, proporcionando control total de los datos y optimización del rendimiento.
Características principales de Llama-3.3-70B¶
-
Arquitectura de alto rendimiento: el modelo tiene 70 mil millones de parámetros y está optimizado para procesar tareas complejas con una precisión inigualable mediante tecnologías modernas de computación distribuida;
-
Integración con Open Web UI: una interfaz web moderna disponible en el puerto 8080, que garantiza el control total sobre los datos, los recursos de computación y los procesos de procesamiento;
-
Computación distribuida: soporte avanzado para configuraciones de múltiples tarjetas con equilibrio de carga automático entre varias GPUs;
-
Escalabilidad: capacidad de escalar horizontalmente añadiendo GPUs adicionales para aumentar el rendimiento;
-
Rendimiento: uso de la tecnología LLAMA_FLASH_ATTENTION para optimizar los cálculos y acelerar el procesamiento de solicitudes;
-
Tolerancia a fallos: un sistema de recuperación automática garantiza el funcionamiento continuo.
-
Ejemplos de uso:
-
Soporte al cliente: automatización de respuestas a consultas de usuarios;
-
Educación: creación de materiales educativos, asistencia en la resolución de problemas;
-
Marketing: generación de textos publicitarios, análisis de reseñas;
-
Desarrollo de software: creación y documentación de código.
-
Funcionalidades de implementación¶
| ID | Nombre del Software | SO Compatible | VM | BM | VGPU | GPU | CPU Mín. (Núcleos) | RAM Mín. (GB) | HDD/SSD Mín. (GB) | Dominio Personalizado | Activo |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 253 | Llama-3.3-70B | Ubuntu 22.04 | - | - | + | + | 4 | 64 | - | No | PEDIR |
-
El tiempo de instalación es de 15 a 30 minutos, incluido el sistema operativo;
-
El servidor Ollama carga y ejecuta el LLM en la memoria;
-
Open WebUI se implementa como una aplicación web conectada al servidor Ollama;
-
Los usuarios interactúan con el LLM a través de la interfaz web de Open WebUI, enviando solicitudes y recibiendo respuestas;
-
Configuración para computación distribuida en sistemas de múltiples tarjetas;
-
Sistema de monitorización del estado, incluida la temperatura y el rendimiento de la GPU;
-
Optimización del trabajo paralelo de múltiples aceleradores gráficos;
-
Todos los cálculos y el procesamiento de datos se realizan localmente en el servidor. Los administradores pueden configurar el LLM para tareas específicas mediante las herramientas de OpenWebUI.
Requisitos del sistema y especificaciones técnicas¶
-
Acelerador gráfico con soporte CUDA (una de las opciones, puede haber mejores):
- 1x NVIDIA H100
- 2x NVIDIA A100 (48 GB de memoria de vídeo cada una)
- 2x NVIDIA RTX 5090 (32 GB de memoria de vídeo cada una)
- 2x NVIDIA A6000 (48 GB de memoria de vídeo cada una)
- 3x NVIDIA RTX 4090 (24 GB de memoria de vídeo cada una)
- 3x NVIDIA A5000 (24 GB de memoria de vídeo cada una)
-
Espacio en disco: SSD de tamaño suficiente para el sistema y el modelo;
-
Software: controladores NVIDIA y CUDA;
-
Uso de memoria de vídeo: 53 GB con un contexto de 2K tokens;
-
Monitorización del sistema: comprobación exhaustiva del estado de los controladores, los contenedores y la temperatura de la GPU.
Primeros pasos después de implementar Llama-3.3-70B¶
Tras el pago, se enviará un correo electrónico a la dirección registrada notificando que el servidor está listo para trabajar. Incluirá la dirección IP del VPS, así como la información de inicio de sesión y contraseña para conectarse al servidor y un enlace para acceder a OpenWebUI. Los clientes de nuestra empresa gestionan el equipo a través de el panel de gestión de servidores y la API — Invapi.
-
Datos de autenticación para acceder al sistema operativo del servidor (por ejemplo, mediante SSH) se le enviarán en el correo electrónico recibido.
-
Enlace para acceder al panel de control de Ollama con la interfaz web Open WebUI: bajo la etiqueta webpanel en la pestaña Configuration >> Tags de la consola de gestión de Invapi. El enlace exacto en el formato
https://llama<Server_ID_from_Invapi>.hostkey.inse envía por correo electrónico al entregar el servidor.
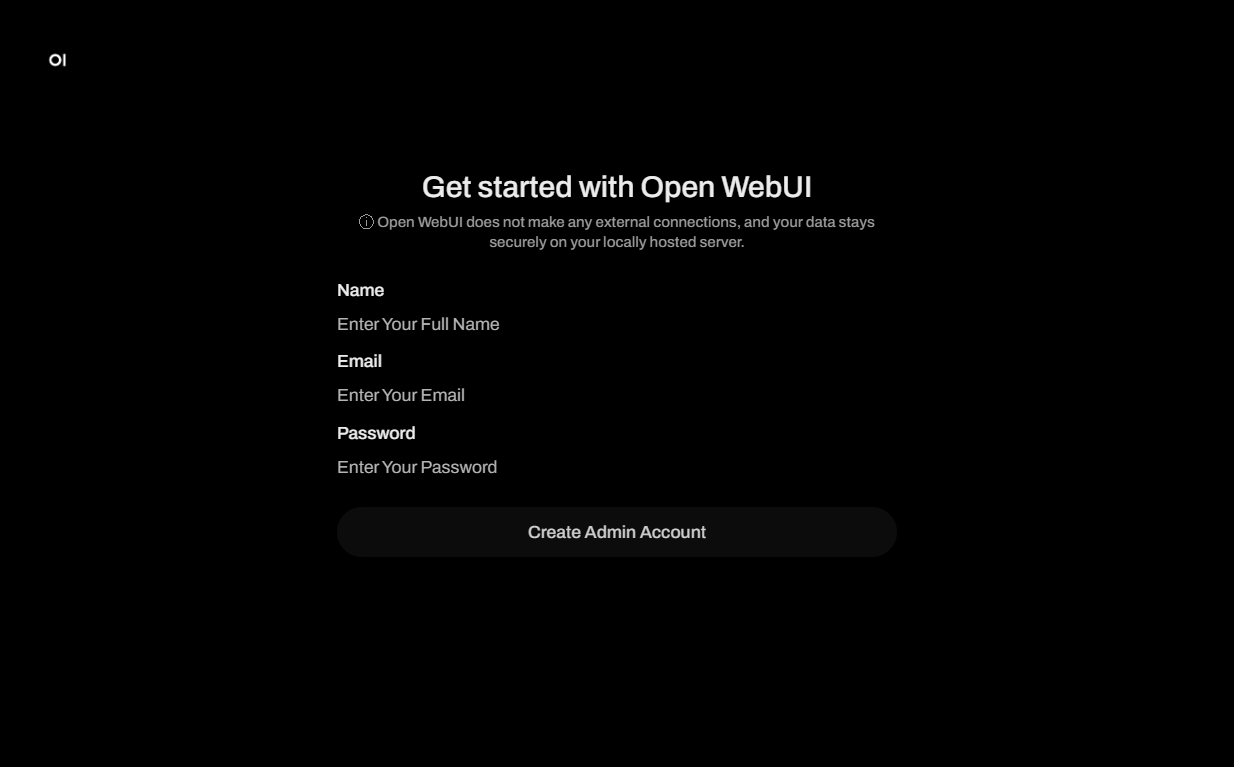
Al hacer clic en el enlace de la etiqueta webpanel, se abrirá una ventana de inicio de sesión Get started with Open WebUI, donde deberá crear un nombre de cuenta de administrador, un correo electrónico y una contraseña para su chatbot, y luego presionar el botón Create Admin Account:
Atención
Después de registrar el primer usuario, el sistema les asigna automáticamente un rol de administrador. Para garantizar la seguridad y el control sobre el proceso de registro, todas las solicitudes de registro posteriores deben aprobarse en OpenWebUI desde la cuenta de administrador.
Nota
Puede encontrar información detallada sobre el trabajo con el panel de control de Ollama con Open WebUI en el artículo Chatbot de IA en su propio servidor.
Nota
Para un rendimiento óptimo, se recomienda utilizar GPUs con más de los 16 GB de memoria de vídeo mínimos requeridos. Esto garantiza un margen para procesar contextos más grandes y solicitudes paralelas. Puede encontrar información detallada sobre la configuración principal de Ollama y Open WebUI en la documentación de los desarrolladores de Ollama y en la documentación de los desarrolladores de Open WebUI.
Pedido de un servidor con Llama-3.3-70B mediante API¶
Para instalar este software utilizando la API, siga estas instrucciones.