gpt-oss-120b¶
En este artículo
Información
gpt-oss-120b es un modelo a gran escala con pesos abiertos de OpenAI, diseñado para tareas de alto rendimiento que requieren razonamiento profundo, planificación en múltiples pasos e interacción compleja con herramientas. El modelo contiene 120 mil millones de parámetros, de los cuales aproximadamente 21 mil millones se activan por pasada, proporcionando un equilibrio entre potencia computacional y eficiencia. Gracias a métodos avanzados de cuantización y optimización, gpt-oss-120b puede implementarse en hardware de servidor con 70 GB o más de memoria de video y admite implementación local o híbrida escalable.
Características principales de gpt-oss-120b¶
- Arquitectura escalable con activación condicional: El modelo contiene 120 mil millones de parámetros, pero a través del mecanismo de activación dispersa (sparse activation), solo activa aproximadamente 21 mil millones de parámetros por solicitud. Esto reduce significativamente los requisitos de memoria y recursos computacionales sin comprometer la calidad.
- Capacidades avanzadas de agente: gpt-oss-120b admite un conjunto extendido de herramientas, incluyendo ejecución de código, búsqueda web en tiempo real, llamadas a API y generación de estrictamente estructurados (JSON, XML, etc.). Esto lo convierte en una base ideal para agentes autónomos y sistemas automatizados complejos.
- Razonamiento adaptativo: El modelo implementa un sistema flexible de niveles de razonamiento: desde respuestas directas rápidas hasta cadenas de pensamiento en múltiples pasos (chain-of-thought) y árboles de decisión. Los usuarios pueden controlar la "profundidad de pensamiento" dependiendo de la complejidad de la tarea.
- Alto rendimiento en benchmarks: gpt-oss-120b demuestra resultados comparables a modelos propietarios en los niveles o3 y o4, particularmente en tareas que requieren lógica, matemáticas, programación y síntesis interdisciplinaria de conocimiento.
- Amplio soporte multilingüe: El modelo está entrenado con datos de más de 50 idiomas y puede operar eficazmente en contextos multilingües y multiculturales. Para obtener los mejores resultados, se recomienda especificar explícitamente el idioma y los marcos culturales en el prompt.
- Cuantización eficiente y compatibilidad: El soporte para formatos MXFP4 e INT4 permite una reducción significativa del uso de memoria y una aceleración de la salida sin una pérdida sustancial de calidad. El modelo es compatible con frameworks populares como vLLM, GGUF y Hugging Face Transformers.
Funcionalidades de implementación¶
| ID | Nombre del Software | SO Compatible | VM | BM | VGPU | GPU | CPU Mín. (Núcleos) | RAM Mín. (GB) | HDD/SSD Mín. (GB) | Dominio Personalizado | Activo |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 415 | gpt-oss:120b | Ubuntu 22.04 | - | - | + | + | 16 | 128 | 240 | No | PEDIR |
Especificaciones técnicas del entorno:
- Ubuntu 22.04 con kernel actualizado a la versión 6;
- Últimos controladores Nvidia;
- CUDA Toolkit;
- Ollama para la gestión de modelos;
- OpenWebUI para la interfaz web.
Características de la instalación:
- El tiempo de instalación es de 35-45 minutos, incluida la configuración del SO;
- El servidor Ollama carga y ejecuta el modelo gpt-oss-120b en la memoria GPU/RAM;
- Open WebUI se implementa como una aplicación web conectada al servidor Ollama;
- Los usuarios interactúan con el modelo a través de la interfaz web de Open WebUI para tareas de programación y agentes;
- Todos los cálculos y el procesamiento de código ocurren localmente en el servidor;
- Los administradores pueden configurar el modelo para tareas de desarrollo específicas utilizando las herramientas de OpenWebUI;
- Soporte para varios niveles de cuantización para optimizar el uso de memoria.
Primeros pasos después de implementar gpt-oss-120b¶
Tras el pago, se enviará una notificación sobre la disponibilidad del servidor al correo electrónico registrado durante el pedido. Incluirá la dirección IP del VPS, el nombre de usuario y la contraseña para acceder al servidor, así como un enlace al panel de control de OpenWebUI. Los clientes gestionan el equipo a través del Panel de gestión de servidores y API — Invapi.
- Credenciales para acceder al servidor del SO (por ejemplo, vía SSH) se enviarán en el correo electrónico recibido.
- Enlace al panel de control de Ollama con la interfaz web de Open WebUI: en la etiqueta webpanel en la pestaña Configuration >> Tags del panel de control de Invapi. El enlace exacto, por ejemplo,
https://gpt-oss<Server_ID_from_Invapi>.hostkey.in, se proporciona en el correo electrónico enviado al entregar el servidor.
Al visitar por primera vez el enlace de la etiqueta webpanel, se abrirá una página de bienvenida. Haga clic en el botón Get started para comenzar la configuración.
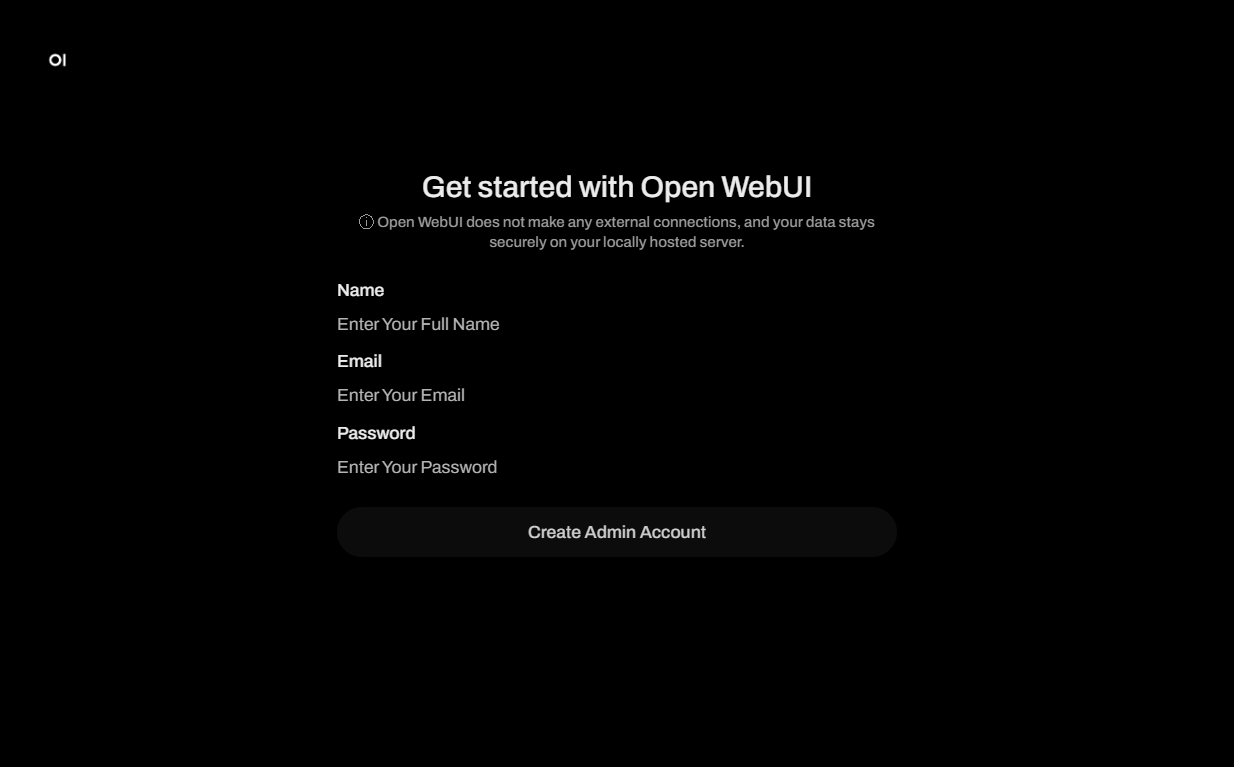
Después de hacer clic en el enlace de la etiqueta webpanel, se abrirá una ventana de inicio de sesión Get started with Open WebUI, donde deberá crear un nombre de cuenta de administrador, correo electrónico y contraseña para su chatbot, y luego presionar el botón Create Admin Account:
Atención
Después de registrar el primer usuario, el sistema les asigna automáticamente un rol de administrador. Para garantizar la seguridad y el control sobre el proceso de registro, todas las solicitudes de registro posteriores deben aprobarse en OpenWebUI desde la cuenta de administrador.
Tras un registro exitoso, se abrirá la interfaz principal de Open WebUI con acceso a gpt-oss-120b:
Nota
Información detallada sobre el uso del panel de control de Ollama con Open WebUI se puede encontrar en el artículo Chatbot de IA en su propio servidor.
Nota
Para un funcionamiento óptimo con el modelo gpt-oss-120b, se recomienda utilizar una GPU con al menos 70 GB de memoria de video para el modelo 120B. Para un procesamiento eficiente de contextos de código largos y tareas de agente complejas, recomendamos utilizar GPUs con 80 GB de memoria de video. Información detallada sobre la configuración principal de Ollama y Open WebUI se puede encontrar en la documentación del desarrollador de Ollama y en la documentación del desarrollador de Open WebUI.
Recomendaciones de uso
Para maximizar la eficiencia del modelo gpt-oss-120b, se recomienda:
- Utilizar el modelo para tareas de razonamiento, incluido el procesamiento de cadenas de pensamiento. El modelo admite niveles de razonamiento ajustables: bajo, medio y alto, que se configuran a través de un prompt del sistema.
- Aprovechar las capacidades integradas del agente del modelo, como llamadas a funciones, ejecución de código Python y salidas estructuradas.
- Emplear el modelo para tareas de desarrollo en múltiples etapas aprovechando sus capacidades de agente.
- Integrar el modelo con las herramientas de desarrollo existentes a través de la API, teniendo en cuenta que admite ajuste y opera en el formato de respuesta OpenAI Harmony. El modelo está diseñado para una implementación eficiente con baja latencia, incluida la local.
Pedido de un servidor con gpt-oss-120b usando la API¶
Para instalar este software utilizando la API, siga estas instrucciones.